

Machine Learning and Artificial Intelligence (ML/AI) are two of the biggest buzzwords in the tech industry at the moment. The technologies have wide application, much greater than the often-repeated stories about self-driving cars. ML/AI solutions can be used in healthcare to improve diagnostics. It has applications across the financial world, allowing companies to be more competitive or spot anomalous trading. It’s being use in retail, to improve recommendations and be more accurate in customer services (think of how much you hate when that Amazon package doesn’t arrive on time).
Driving the ML/AI revolution is data. It’s estimated we’ll create 163 zettabytes of content per year by 2025, much of it coming from automated sources, like sensors and cameras. That’s in addition to user-created content (think of all those cat pictures and videos) and user-generated data from log files. I case you’re wondering, zettabyte comes after exabyte and is one million petabytes. As a reference guide, Seagate shipped around 87 exabytes of HDD capacity during 3Q2018 (see the image here).

Machine learning requires training computers using new algorithms through the processing of huge datasets of sample data. This is the new world of deep learning where linear improvements in accuracy are gained through exponential growth in the training data set. Let’s just think about that for a moment – to get the degree of accuracy we need and want from machine learning, we have to throw masses of data into algorithms – and that’s a problem.
Latency & Throughput
Persistent storage has always been the slowest part of any IT infrastructure. Flash storage has definitely improved that situation, but the industry continues to strive for more throughput and lower latency with every iteration of technology. As we look at the needs of ML/AI, it becomes obvious that both latency and bandwidth are key factors in training algorithms.
Systems could take months to train correctly. Imagine finding out your algorithm is inaccurate after waiting 2 months to see the results. Shortening the learning time has positive benefits, both from getting to the results quicker and from increasing the ability to iterate through improvements to training algorithms to get the process right.
Simply put, whenever exponential levels of data are being processed, then every piece of latency and throughput improvement has a benefit.
AI Pipeline

The typical AI pipeline (see figure 3) goes through a number of stages. Data is ingested from a range of sources. It’s cleaned and transformed using traditional platforms. After that, the data is tested and explored to see how various models might work. This is the point where we see bespoke technology being used. GPUs (Graphics Processing Unit) provide the horsepower to do AI processing. More on that in a moment. The I/O profile at each stage of processing varies, with read and write biases, random and sequential biases and high concurrency (parallel access) in the training stage.
NVIDIA GPUs
GPUs such as NVIDIA’s Tesla V100 processors are designed to process ML/AI data sets, with each GPU having the processing power of about 100 general CPUs.
NVIDIA uses a programming platform and API called CUDA. This takes data from main memory, into the GPU where it is executed in parallel across the internal cores before the results are returned to main memory. The performance of NVIDIA GPUs is expressed in CUDA cores and tensor cores. Tensorflow is another open-source machine learning platform developed by Google that works on tensors, mathematical constructs used to represent relationships between geometric vectors and scalars.
The V100 processor has 640 tensor cores, individual ALUs (arithmetic logic units) capable of performing operations on tensors. It also supports 5120 CUDA cores. GPUs are highly demanding on I/O, with a single V100 capable of 900GB/s of memory bandwidth. Internally, NVIDIA DGX-1 AI workstations use NVIDIA NVlink, a custom interlink technology that has 10x the performance of PCIe. This allows each V100 to support up to 300GB/s of throughput (or 32GB/s with PCIe). Each DGX-1 has eight V100 GPUs, dual 20-core Intel Xeon processors and Infiniband and 10GbE connections.
Bandwidth
It’s clear that AI systems using the NVIDIA DGX-1 architecture need to be connected to fast storage, with high throughput and low latency. Data access in training AI algorithms is typically random read on small files, which can be hard for many storage platforms to deliver. Randomness can defeat the benefits of caching, so all-flash systems provide guaranteed low latency access, regardless of the data profile.
Pure FlashBlade

Pure Storage introduced FlashBlade at Accelerate in 2016. The architecture is a scale-out NAS and object store, built from custom hardware. Each blade in the system has NAND flash, NVRAM, ARM cores and FPGAs to provide a distributed architecture which scales linearly with each blade added.
At the time of launch, it was unclear how this new architecture would be deployed by enterprises. The platform wasn’t a direct replacement for traditional NAS (although it is now seeing some uses in that way). The idea of all-flash meant that there was a different cost profile to usage compared with traditional file-based storage. When most data is inactive, it’s difficult to justify putting all of the data on flash. However, it’s now clear that the intended target for FlashBlade was always high-performance workloads that needed consistent performance.
AIRI
{kind=link}

So, if you have high-performance file-based storage requirements and a high-performance file platform, why not put them together? This is exactly what Pure Storage has done in building out the AIRI platform.
AIRI is a combination of FlashBlade, NVIDIA DGX-1 servers and high-performance networking that provides a bespoke AI architecture. Why deliver this as a hardware offering when customers could take the components themselves? I asked this question of Roy Kim, Pure’s AI Lead and Director of Products and Solutions. His answer was pretty simple – customers don’t want to do the design and integration work themselves, but would rather take a tested and validated solution, especially when many enterprises don’t have lots of experience in building ML/AI solutions.
CI for AI
{kind=link}

Effectively, Pure is offering converged infrastructure for ML/AI. Compare this to the way in which CI solutions are developed and there are some obvious parallels. CI removes the overhead of having to select components and to do integration testing. The vendor validates updates and patching. In many cases the deployment of fixes is implemented by the vendor too.
Think how this compares to AIRI. Pure Storage does the work of validating the architecture and testing the scalability of DGX-1 servers with FlashBlade. At the same time, there’s a clear linear scaling capability. If more storage capacity/bandwidth is required, add more FlashBlades. If more compute is required, add more DGX-1 servers.
Of course it’ not just about putting hardware components together. Like CI, AIRI is shipped with integrated software, including the AIRI Scaling Toolkit, allowing customers to quickly get up and running with the minimum of effort.
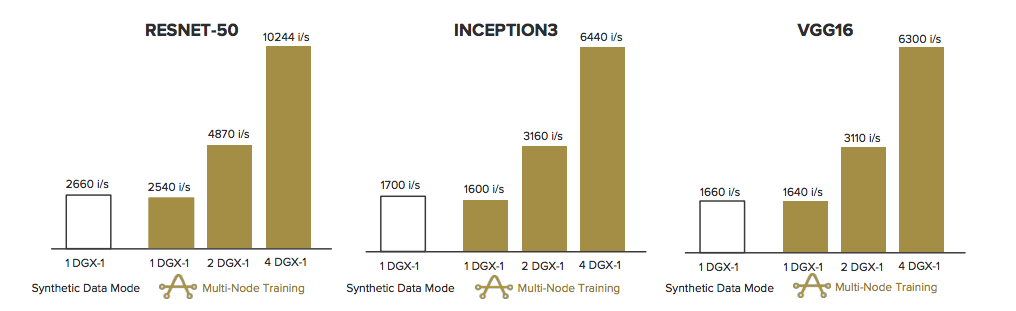
Pure has published results that shows how the AIRI architecture scales with increased infrastructure. The figures are based on standard AI frameworks and synthetic workloads, including RESNET-50, INCEPTION3 and VGG16. In each case, the results show linear scaling compared to a single node synthetic workload.
The Architect’s View
I was really impressed with the idea of FlashBlade when it was first announced. The team at Pure has always been keen to explain exactly how the FlashBlade architecture was designed for scale, but what is the practical use of an all-flash file product?
I always expected that Pure would need to seed the market with “application ideas”. Basically take FlashBlade and show customers how it could be used. Alternatively, partner with companies and build reference architectures like AIRI.
I have a feeling that AIRI is just the first of a number of reference architecture solutions that will build on top of the FlashBlade platform. With the move to containerisation for modern applications, the ability to create hugely parallel workloads will demand hugely parallel storage. The applicable use cases really depends on customer imagination. I’m looking forward to seeing what other architectures are developed and seeing what customers have managed to achieve that couldn’t otherwise have been done before.
Further Reading & Watching
For more information on the FlashBlade architecture, I recommend the following presentation from Rob Lee, Chief Architect of the FlashBlade platform.
Scaling Pure Storage FlashBlade with Robert Lee from Stephen Foskett on Vimeo.
As a little pre-cursor to the concept of AIRI, this video from Brian Gold provides some background context on how Tensorflow could be used with FlashBlade.
Object Storage in Pure Storage FlashBlade with Brian Gold from Stephen Foskett on Vimeo.
Comments are always welcome; please read our Comments Policy. If you have any related links of interest, please feel free to add them as a comment for consideration.
Copyright (c) 2009-2018 – Post #126F – Brookend Ltd, first published on https://www.architecting.it/blog, do not reproduce without permission. Disclaimer – Pure Storage is a customer of Brookend Ltd. Chris was invited to Pure Accelerate 2018, with Pure covering air fare and accommodation. There is no requirement to produce content as a result of the event.