

This post is the third of a series of independently written technical briefings on the AWS S3 API and how it has become the de-facto standard for object stores. The series is commissioned by Cloudian Inc. For more information on Cloudian and the company’s HyperStore object storage technology, please visit their site at: http://www.cloudian.com/
Webinar: Join me to learn everything you need to know about the S3 API in a free webinar sponsored by Cloudian on 23rd March 2016 8am PDT, 3pm GMT
In previous posts we looked at an overview of the S3 API and some of the security features that cover data access. In this post we will look at some of the advanced features of the API and in particular some of the places in which vendors providing products with S3 API compatibility can add value.
Versioning

Versioning allows multiple copies of an object to be stored within the same bucket. This can be used to provide a historical record, or to protect against overwriting or deletion. The versioning feature is turned on at the bucket level, with a bucket being configured to one of three states; unversioned, versioning enabled or versioning suspended. All buckets start in the unversioned state and once enabled for a bucket, versioning cannot be turned off, only suspended.
Versions of an object are tracked with a VersionID, a characteristic of all objects. When versioning is not enabled, the VersionID of an object is stored as a null value. With versioning enabled, each PUT (update) request for an object stores the object with a unique VersionID, a randomly generated character string of up to 1024 bytes in length.
As objects are updated and stored with a unique VersionID, each copy of the object is retained in the bucket and can be accessed by name (in which case it retrieves the latest or current copy) or by name and VersionID. If an object is deleted from a bucket, GET (read) requests return an error, unless the VersionID is also included. A deleted object can be restored by issuing a COPY request and including a specific VersionID.
AWS offers no cost reduction on the de-duplication of updated objects, so if only a small portion of an object is updated, each version occupies the full capacity – 5 copies of an object occupy 5x the space and cost, even when an object is deleted. This means implementing versioning can quickly become expensive in AWS and this provides object store vendors one opportunity to reduce costs while still offering S3 API compatibility. Object storage with deduplication can represent a significant saving over AWS when versioning is in place.
Tiering
AWS offers multiple categories or classes of storage within S3. Each class offers the same level of durability (risk of data loss/corruption) but comes with varying levels of availability and access times. S3 tiers are: Standard, Standard – Infrequent Access (IA) and Glacier.
| Standard | Standard – IA | Amazon Glacier | |
| Durability | 99.999999999% | 99.999999999% | 99.999999999% |
| Availability | 99.99% | 99.9% | N/A |
| Availability SLA | 99.9% | 99% | N/A |
| Minimum Object Size | N/A | 128KB | N/A |
| Minimum Object Duration | N/A | 30 days | 90 days |
| Retrieval Fee | N/A | per GB retrieved | per GB retrieved |
| First Byte Latency | milliseconds | milliseconds | 4 hours |
| Storage Class | object level | object level | object level |
| Lifecycle Transitions | yes | yes | yes |

Data is moved between classes using Lifecycle management, which determines how data is managed from creation to destruction. Lifecycle policies determine how data within a bucket is managed between the multiple storage layers in S3. For example, a policy can be established to move all items in the “archive/” folder to Glacier after 365 days (known as a Transition) and then to delete the content after 10 years (an Expiration) from the date of creation.
In addition to the Transition and Expiration actions, S3 provides the ability to perform the same actions on versioned buckets with NoncurrentVersionTransition and NoncurrentVersionExpiration respectively. These features allow older versions of objects to be actioned in a different way to the current versions, so the inactive copies can be moved out more quickly to cheaper storage.
Obviously AWS has very rigid storage classes, however the S3 API does provide the ability to specify generic storage tiers as part of the migration action, as the target for migration is simply defined by the StorageClass parameter. This provides object storage vendors the capability to implement much richer data management policies that cater for many tiers of storage which can be defined outside of the API, without deviating from the standards of the API itself.
Replication
The S3 API provides the ability to replicate data between AWS regions. AWS defines a region as a resilient group of geographically close data centres. S3 provides resiliency between data centres within a region, but there may be good reasons for protecting data between regions, for example, for compliance or to put data closer to an application and reduce latency overhead.
Replication is implemented at the bucket level and acts as an asynchronous (or eventually consistent) task. All data within a bucket, or a subset defined by prefix can be replicated, with each object, including Object ID, versions and metadata transferred to the target bucket. AWS only permits a one-to-one relationship between a source and target bucket and unless specified, the target bucket will be based on the same storage class as the source.
Replication, versioning and region resilience provide the capability to protect against most data loss situations, including user error, application data corruption and hardware failure. What these features don’t provide is a guarantee that data is definitely safely stored in more than one location when an initial object PUT (save) request is issued. This may cause compliance issues for some businesses and so object store vendors have the ability to improve replication capabilities by implementing synchronous replication where appropriate for the right type of data.
Logging and Billing
S3 offers the capability to log all actions made through the S3 API. The data is stored in another AWS product called CloudTrail, that tracks all API calls, not just those performed with S3. Obviously the ability to trace activity is an important piece of any storage infrastructure and provides the basis for auditing and compliance. CloudTrail is offered by AWS at a very low cost but isn’t free. In addition, data logged is stored in an S3 bucket owned by the customer and retaining large amounts of logging data will accrue costs over time.
Billing is managed at the account level, however tags can be associated with buckets to align charging to business units. The use of tags is entirely freeform and not interpreted in any way by S3, therefore the account owner is responsible for ensuring that billing maps to data owners within a single account.
Encryption
In the previous post we talked about the security aspects of controlling access to data. S3 provides two other additional features to ensure data is protected for access only by authorised parties – data-at-rest encryption and encryption of data-in-flight.
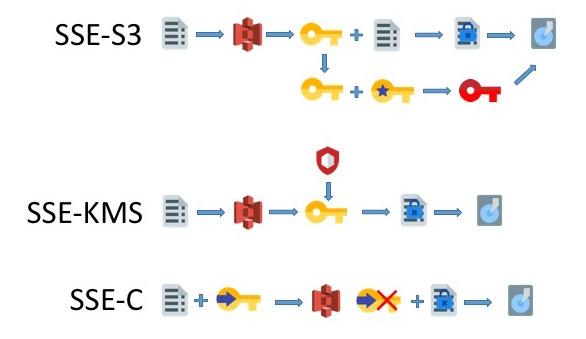
Data at rest within S3 can be encrypted using either Server-side encryption (SSE) or Client-side encryption. Server-side encryption provides three options to the user; encryption using S3 managed keys (known as SSE-S3), encryption with keys stored in S3’s key management service (KMS), known as SSE-KMS and encryption using customer-provided keys (SSE-C). In all three options, AWS manages the encryption process, however each provides different levels of protection. SSE-KMS, for example provides more detailed audit tracking and permissions to control the use of keys. SSE-C takes key management away from AWS, putting responsibility into the hands of the user, including ensuring that keys are properly managed and stored.
It’s important to note that when using the S3 REST API, the user is responsible for the encryption process when looking after their own key management (SSE-C). However, encryption using SSE-S3 or SSE-KMS can be specified in the request header on a PUT (save) request. AWS also provides the option to use an encryption client in the SDKs for Java, Ruby and .NET that take away some of the overhead of the encryption process.
Client-side encryption provides two options and requires the user to encrypt data before sending it to AWS. This can be achieved using AWS KMS managed keys, in which case the client only needs to use the KMS master key. Alternatively, data can be encrypted by the client before sending to S3.
Data in flight is protected using SSL when storing and retrieving content via the API. However, when using S3 as a website endpoint, HTTPS isn’t supported and customer have to use CloudFront.
Summary
From the features described in this post, we can see that the API offers some advanced features that enable data protection, data management and efficiency. Most of these features can be implemented by object storage vendors in a way that extends the capability of the features (e.g. multiple storage tiers, synchronous replication, de-duplication and compression) without compromising on the underlying standards of S3. This highlights two important factors about S3 compatibility; first that vendors should be supporting all the features in their entirety and second, that with 100% compatibility, vendors have the ability to extend the API providing a superset of functions that can’t be achieved with a purely public cloud deployment.
Further Reading
- Object Storage: Standardising on the S3 API
- Object Storage: S3 API and Security
- 2016 – Object Storage and S3
- WEBINAR: Everything you need to know about the S3 Object Storage Service and S3 API Compatibility (Cloudian website, retrieved 7 March 2016)
- Amazon Simple Storage Service Developer Guide (AWS Website, retrieved 7 March 2016, PDF)
Comments are always welcome; please read our Comments Policy first. If you have any related links of interest, please feel free to add them as a comment for consideration.
Copyright (c) 2007-2020 – Post #A3B7 – Brookend Ltd, first published on https://www.architecting.it/blog, do not reproduce without permission.