
I frequently hear (and read) the comment that backup agents are a bad idea. Pretty much all of those statements are made without any context as to why installing and using agents is a problem. So, what are the issues, and should we be avoiding the use of agents altogether in data protection?
Early Days

Data protection (by which we generally mean backup) has gone through several transitions over the years. As we moved away from monolithic mainframes, applications were deployed on individual servers, typically with one server per application. Note: in many cases there were multiple architectures in play here, such as tiered database and web servers on physical infrastructure, or large multi-use database servers, but in general, especially in the Windows world, we saw one server, one application.
- Managing Legacy Backups
- Application-Focused Backups
- Nutanix Mine Puts Backup Software Vendors on a Level Playing Field
Installing and running backup software on each server is a thankless and non-trivial task, bearing in mind each would need a dedicated backup target – typically a tape drive. Tapes have to be fed and watered (replaced each day) and this becomes impractical once systems scale to more than a dozen or so physical machines.
Centralisation
We quickly moved to centralisation of backup using software such as NetBackup, TSM and Networker. A central set of backup servers provides scheduling and data mover capabilities that can be scaled to meet demand. Now the target tape drive (or de-duplicating appliance) sits behind a backup media server and is available for all servers to use. This introduces the challenge of getting data from the host to the media server – the job of a host agent.
Agents
An agent is a small piece of software installed into a host that acts as a conduit to move data from the host to a media server. The agent identifies changed data, sending it to the media server across the network (usually TCP/IP, but some solutions support Fibre Channel). The use of agents is challenging because:
- Agent software needs installation, configuration, updating, patching and general management. This is a big challenge (although many backup software platforms look to automate this) to administer, creates dependencies on O/S upgrades and introduces additional steps to O/S deployments.
- Agents are installed directly onto an operating system, which introduces security issues. The agent has access to all data on the host and so could be used as an attack vector to get into a server. If you can access the backup agent directly, you potentially have access to every server on which it is deployed.
- Data transfer comes from the network to which a host is attached. In physical environments this means co-ordinating traffic to avoid flooding the network or installing a dedicated backup sub-LAN. In virtual environments where VMs are typically oversubscribed on the network, significant bottlenecks can occur (more on this later).
- Some vendors implement licensing based on the number of agents installed, introducing additional administration to keep on top of removing unused agents and optimising licence costs.
- Agent processing consumes resources (CPU & memory) on the host that could impact application performance if not managed correctly.
Virtualisation
The introduction of virtualisation provided the ability to avoid many of the agent pitfalls. Instead of taking data directly from each VM guest, the hypervisor vendors provide APIs that deliver access to changed data per virtual machine (for example VMware vSphere Storage APIs, or VADP as it was previously known). In this instance, agents are redundant at the guest level and the backup software simply needs credentials to access the API.
The transition to backup APIs removes many of the challenges we’ve previously discussed. Now the hypervisor decides what data the backup software can access. It reduces networking challenges by not using the front-end application network. There is no longer any software to install. The backup software just needs to support the latest version of the API.
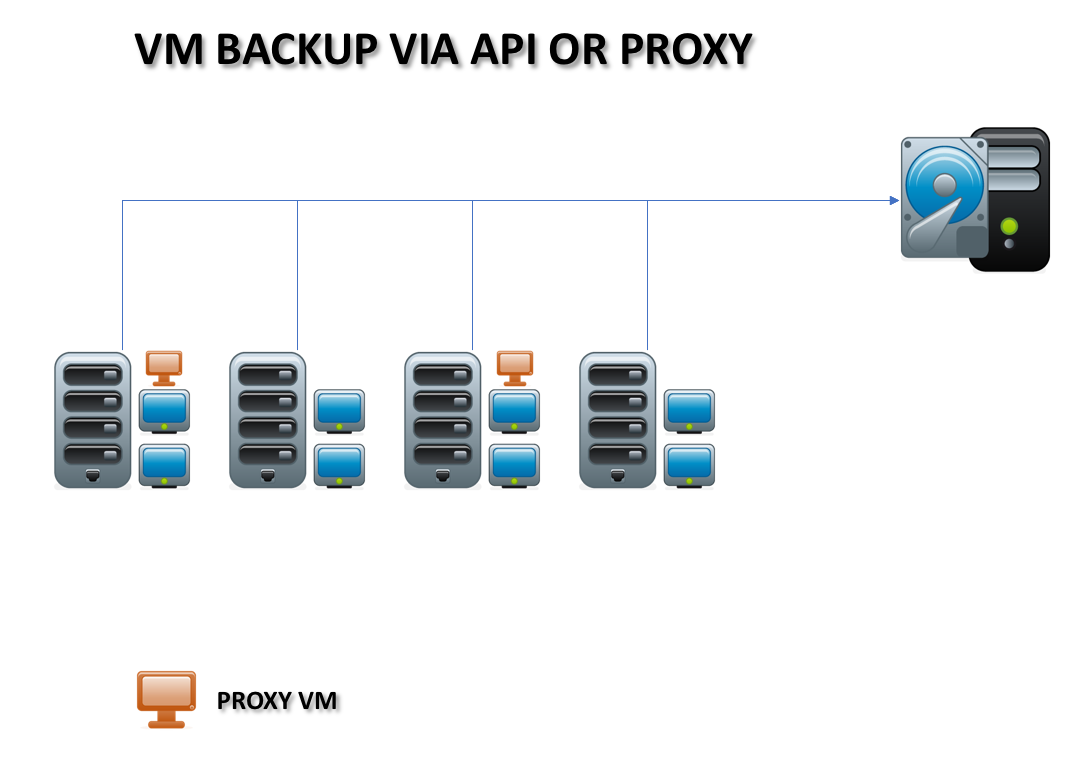
Proxies
In some scenarios, proxies are necessary to act as a gateway for the backup system. This may be because of latency challenges, to enable client-side de-duplication or to optimise data transfer for bandwidth savings. Proxies can also distribute the backup load and be aligned, for example, with multiple virtual server clusters.
A proxy differs from an agent because the proxy software runs alongside the servers being backed up, rather than on them. This is true, even if the proxy runs as a virtual machine on the same platform as the clients being protected.
Blurred Lines
Of course, there will be scenarios where the proxy/agent paradigm becomes blurred. For example, if a backup solution pushes a script to a database host to trigger a dump command, is that an agent? It could be argued that a non-compiled script, either local or executed remotely is not O/S dependent and that a script doesn’t provide an attack vector like an agent. However, that assumes the backup administrator knows exactly what any script is doing when it runs on a host. The backup software also needs to store the ssh key, which exposes all servers if the backup server itself is compromised.
The Architect’s View
Given the choice, the best way to take backups is via an API or a process (like snapshots) that doesn’t involve installing software on every backup client. While that can cover most scenarios, there are occasions when agents are still required. Whether a virtual server environment, a NAS storage system or an application (like a database), having the platform provide the data via standard and consistent APIs is far more practical than agents or scripted solutions. Platform vendors should all be providing standard APIs for data protection (as we’ve discussed before) and helping make data protection safe and efficient.
Copyright (c) 2007-2019 Brookend Ltd, no reproduction without permission, in part or whole. Post #d50d.