
It’s always interesting to see new ideas emerge that look to challenge the issues experienced in storage and data management. Yesterday we saw the launch of Ionir, a startup emerging from stealth and what appears to be the ashes of Reduxio. The technology aims to offer instant data mobility and is backed by Jerusalem Venture Partners (JVP). What caught my eye was the remarkable similarity this solution has to one I pitched to JVP some three years ago.
The Challenge
Even five years ago, it was clear we were heading towards a hybrid and multi-cloud world. Here’s a blog I posted 4.5 years ago that reflects on the challenge of making data truly portable across applications and application environments. Data has inertia (not gravity), and that makes it hard to move large quantities of data over time and space. We’re constrained by the speed of light, which effectively limits the propagation of electrons in cables and photons in fibre.
Even if we could move data relatively quickly (which we now can), we also have to consider the data consistency challenges. If I move a 1TB database from on-premises to the public cloud, that database will be out of action until the process completes (unless I have some fancy way of catching up with changes, which is inherently challenging with structured data).
The Solution
Examine any computer system from the mainframe onwards, and you’ll see a common theme. Data is accessed by applications in the form of files. A block device is accessed through a file system that sits above it (bar very few exceptions). Object stores are essentially file stores with no hierarchy (directories) and a web-based access protocol.
File systems contain metadata and allow tracking of application activity at a very granular level. A typical database consists of data areas, indexes, logs and journals. When we understand the I/O profile of an application by looking at the file activity, we can make specific predictions and assumptions.
Compromise
That essentially was the premise of the MobilusIO system I worked on and developed in 2016/2017. File systems and their semantics provide valuable information on how an application accesses data. The I/O profile of traditional database applications, for example, is 100% predictable. A solution like MongoDB or MySQL will perform a standard set of checks on startup, ensuring log files exist (or creating them) and checking sequence numbers in data files. The database will not read every byte of data but assume the data structures are valid through these high-level checks.
So, if we make the compromise that a distributed file system doesn’t need to provide access to every byte of data everywhere at the same time, we can create the illusion of global data availability.
Global File System
The key to developing a distributed data mobility solution is metadata. In a file system, this consists of files and directory structures. Metadata represents a small part of the persistent storage for an application and is easily replicable over distance. If we also assume that only one location is likely to be the “primary” or active copy, then metadata ownership can move around a global cluster and be attributed to the active instance of the application. If the application moves, the metadata is re-synchronised, and metadata ownership transfers to the new location, just for that part of the data.
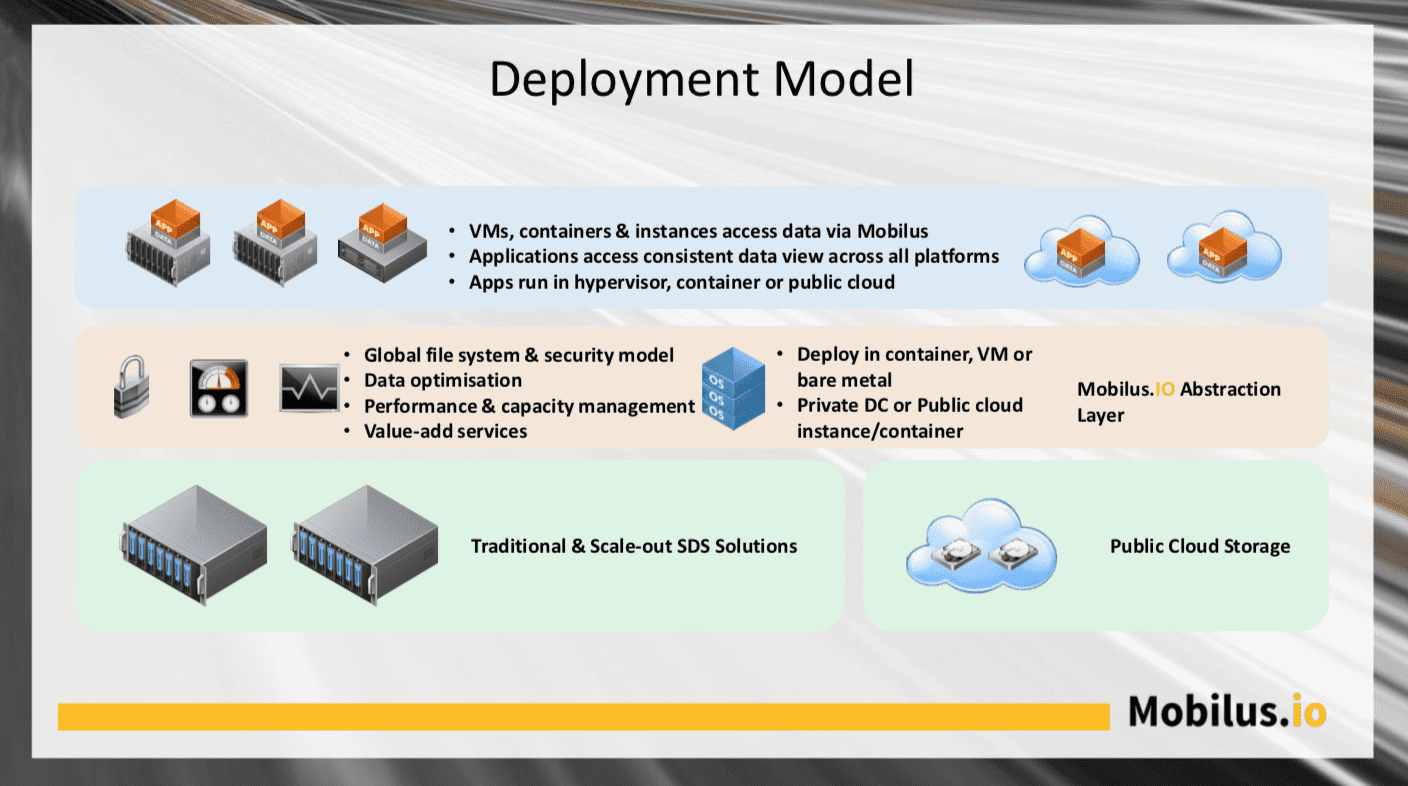
Lazy Writes
As for the actual data component, that moves in the background using a “lazy write” approach. If an application is moving permanently, then the data moves en-masse. If an application is only needed for a brief moment, the data might not move but only be accessed “on-demand”. In either case, if the background copy process is still in progress, a read request generates a “page fault”, and the data is fetched, albeit with increased latency. Writes have no impact as they get stored locally and re-synced the background.
Use Cases
Now, this methodology isn’t suitable for all scenarios. Without adequate knowledge of the application, (read) performance will take a hit because the data isn’t local. The solution has to either know the application or to build some AI that can predict the data profile. This was the aim of MobilusIO, creating that data mobility intelligence.
There are many use cases for this technology.
- Enhanced vMotion – being able to move virtual machines around over distance without full replication.
- Container mobility – moving container-based data between sites and in/out of the public cloud.
- DevOps – replicating data for use in development environments.
- Reducing cloud costs – reducing egress charges for moving application out of the public cloud.

The last two use cases are interesting as they need the use of de-duplication technologies. Imagine you want to copy a database that sits on a file system. Simply replicating a copy of the metadata creates a clone with almost no additional overhead that can be given to developers to use. Each developer could have a complete copy of the production environment if the underlying file system understands data de-duplication.
This kind of technology already exists in today’s file systems (like ONTAP) but imagine stretching the concept over distance. Each public cloud could hold a series of de-duplicated data that represents the building blocks of the file system. If an application moves between clouds, the only data to move are updates and metadata. True multi-cloud mobility.
Pitch
In 2016, I worked with a friend to develop the idea of a globally distributed data mobility solution we called Mobilus (domain name Mobilus.io). Over late 2016 and early 2017, we travelled to Israel multiple times and pitched to a range of venture capital funds with an interest in data management. On 20th February 2017, we pitched at JVP in Jerusalem.
The JVP meeting was interesting because we were told there might be a conflict of interest with the Reduxio team. After meeting a number of partners, including Haim Kopans, we concluded that Reduxio wasn’t competitive and subsequently had a number of follow-up meetings. Of all the potential investors we met, JVP was the closest we came to raising money.

Ultimately, we didn’t manage to persuade any VCs to make a significant investment and decided to shelve the project towards the end of 2017. However, I did build a proof of concept that genuinely worked and could replicate data instantly over thousands of miles for both MongoDB and MySQL (or at least created the illusion).
Hurdles
Building a global data mobility solution is challenging. Here are some of the thought processes we went through.

Platform – is it best to target containers or virtualisation (or both)? The market for containers was (at that time) still mainly focused around Docker. As I outlined in this post, the challenges of persistent data were slowly starting to be recognised, so it was apparent data mobility would be significant. As we now know, Kubernetes has become the dominant container platform, and most persistent storage solutions are block-based, hence the reason for this post. If we want mobility to work, we need to understand the data, and that means a file system. We also spoke to VMware, but the feedback was lukewarm and never pursued.
Data Path – should we build a solution that’s in the data path? Building out a storage platform that replicates data but isn’t inline would have been very hard. Being in the data path also introduces significant challenges, especially around performance. Then that begs the question – should Mobilus simply be an abstraction layer over existing storage or a system in its own right? My feeling was that abstracting existing storage was better, as this would work more effectively in a cloud-based model.
Data Types – My initial thoughts were that virtual machines and container-based applications would be quick and easy to replicate. Unfortunately, these kinds of data are probably more static than we realise. Only now are we starting to consider multi-cloud but having the ability to move workloads around infrastructure doesn’t mean we will want to do it. Change introduces risk, so frequent data and application movement might not deliver the most stable applications.
The most applicable data is likely to be that created at the edge or in vast quantities, where copying is expensive and time-consuming. However, that type of data is generally unstructured and if being used for AI processing, will generate masses of random I/O and defeat any algorithms Mobilus was developing.
The Architect’s View
While we weren’t successful, there are many other solutions that solve some of the data mobility challenges. Hammerspace probably comes the closest to what we were developing (listen here for a podcast with them). For containers, StorageOS and Portworx might eventually be the way to deliver greater mobility. This blog post has more thoughts on the different techniques being used in the market today.
As Ionir seems to have developed from the work done at Reduxio, I think that their solution will be block-based and not have the file-level intelligence required to make this kind of data mobility really work. Time will tell, as we learn more about the solution. From my perspective, I look back at the time as an interesting one, realising that VCs don’t know everything and that a good team is as vital as a good idea.
In the container world, I hope we move more towards file systems rather than block storage because file storage will be essential for serverless, which is the next evolution. File structures make data truly portable across any application packaging, and that’s going to be key to implementing real mobility.
Copyright (c) 2007-2020 – Post #3beb – Brookend Ltd, first published on https://www.architecting.it/blog, do not reproduce without permission.
(the featured image for this post was taken by me on my trip to Jerusalem)