
Update: check out cloud migration posts:
- Cloud Data Migration – Database Import Tools
- Cloud Data Migration – Shipping Virtual Machines
- Cloud Data Migration – Data Transfer Using Physical Shipping & Appliances
I remember going to an HP(E) event back in 2011 (Discover Vegas I think) when the idea of hybrid cloud and converged infrastructure was just getting going. HPE talked about the idea of “cloud bursting” – moving data and/or applications on demand into cloud infrastructure to cope with increased demand. At the time I was massively skeptical of this as an idea. First, unless you had some serious networking into your cloud provider, then getting a VM into somewhere like AWS or Azure could take from minutes to hours, which would be unacceptable in all but the minor of cases (like dev/test). Second, no-one ever talked about data protection and how these now mobile applications would be tracked, secured and recovered in the event of a failure. Remember these are the days before we started talking about “cloud native” apps that were infrastructure tolerant.
If hybrid is to be any use, we need the ability to move applications and data around on demand but retain the following characteristics for our applications and data:
- Consistency – ensure we know which version of our data is the most current and any one time and ensure we protect it and can restore from the most current backup.
- Independence – have the ability to move data to any platform of choice and not be tied to the underlying hardware platform of the infrastructure provider.
- Abstraction – operate on logical constructs, like files, objects, VMs or databases/data objects, rather than having to think in terms of LUNs or volumes.
- Security – implement security features to protect data wherever it is, either in-flight or at rest.
- Ease of Management – to be able to manage the data consistently wherever it sits in the ecosystem.
From a technical perspective, the two main issues to overcome are that of latency and consistency. Latency poses a real problem for data mobility. It introduces data inertia, making it a challenge to move data and applications around the infrastructure without having an impact on normal operations. Consistency is a problem, as creating multiple copies of data makes it more difficult to remember and track which is the most current, or at least to keep one as the master and the others as read-only clones. Scale-out storage platforms like AWS S3 and Swift use the idea of eventual consistency to ensure data gets synchronised across multiple locations over time, however this can lead to applications reading stale data if the sync process lags behind data updates.
Mobility Techniques
There are a number of techniques that can be used to overcome data/application inertia:
- Implement very fast networks.
- Cache data between locations.
- Pre-stage data between locations.
Having a fast network isn’t a total solution as it manages to solve only the throughput and not the latency issues, unless the on/off-premises locations are reasonably close. Caching means providing the ability to access only active content between the source of data and where the application is running. An appliance or software maintains the cache copies and synchronises them back with the single central copy, wherever that is stored. The data itself doesn’t actually move, instead the data path to it is extended. The third option is to pre-stage data in the background for some future migration activity. The application can then be moved to run from the secondary copy as demand requires.
Vendor Implementations
There are a number of vendor implementations in the market looking to solve problems 2 and 3 described above.
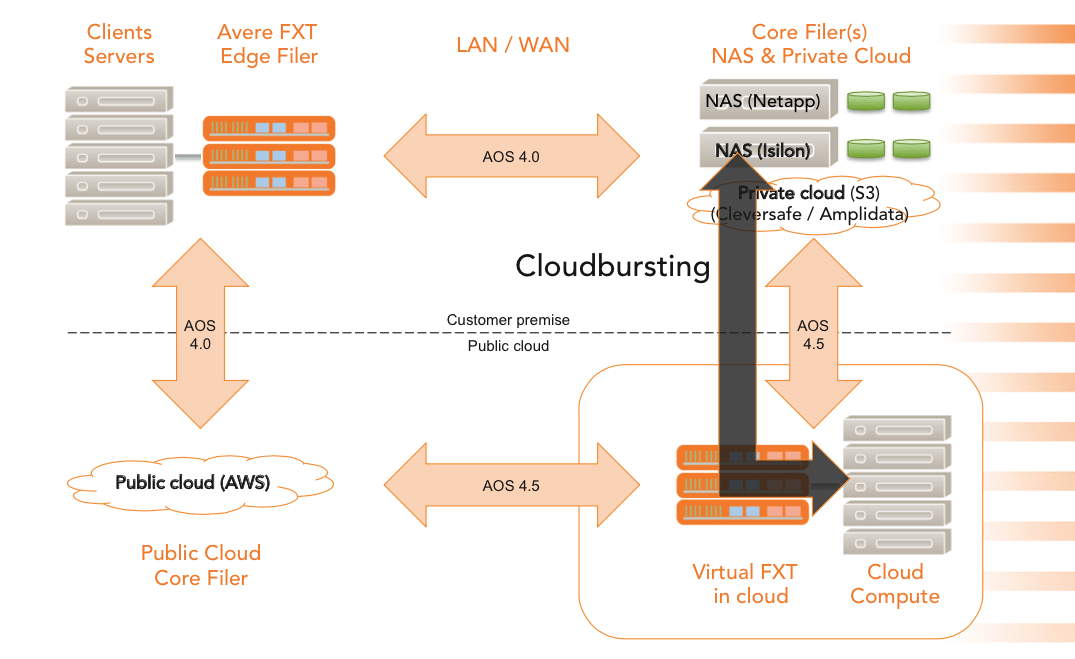
Avere Systems is one vendor I’ve talked about for some time that provides the ability to implement cloud bursting through their vFXT virtual edge filer. vFXT runs as a virtual appliance in platforms such as AWS and extends the visibility of data into the cloud, making it look like cloud-based applications have full local access to data that is in fact stored on premises. Only active data is cached in the vFXT, with write I/O periodically staged back to the core filer system. Avere showed the power of their caching implementation by running the SPEC sfs2008 NFS.v3 benchmark against an edge filer backed by AWS (press release – results here). Obviously latency is mitigated in this solution at the expense of data consistency; until the write I/O is destaged back to the core filer, there’s still a risk.
NetApp

NetApp discussed their concept of the Data Fabric at a recent Tech Field Day event, in this case, Storage Field Day 9. The presentation from Joe CaraDonna (Sr Technical Director, Data Fabric Group), talked about building a “fabric” for data that leverages existing technologies like SnapMirror to move data between local sites and public cloud. NetApp provides a number of solutions to achieve this, such as NetApp Private Storage, where physical appliances are hosted in partner data centres like Equinix and connected to the likes of AWS through Direct Connect or Azure with Express Route.
NetApp also has a public cloud version of ONTAP, known as Cloud ONTAP (great name) that runs as an instance in the cloud provider. Jo CaraDonna showed their intentions with the Data Fabric with a demo of OnCommand Cloud Manager, using the web-based interface to move data around a hybrid infrastructure. You can view the video here, which includes features still in development and not yet released.
NetApp’s Wider Portfolio
With the acquisition of SolidFire, NetApp now has a portfolio that spans traditional (AFF/FAS), high performance (E/EF Series), scale out (SolidFire), object (StorageGRID) and backup (AltaVault). SolidFire is already “software defined” and exists as a software-only play known as ElementX. There is also a virtual implementation of Data ONTAP known as ONTAP Edge. So, NetApp has all the pieces; the trick for them is putting them together in a way that makes Data Fabric operationally acceptable to customers. Most notably is the ability to move data between platforms, for example to take a volume from ONTAP and move it to SolidFire.
Another couple of examples of the pre-staging model come from Zerto and Druva. Both companies have come from the origins of data protection but are slowly pivoting to focus more on data mobility than purely backup into the cloud. Druva’s Phoenix platform, for example allows VMs running on-premises in a VMware environment to be backed up and run within AWS. The Druva software handles the VM conversion within AWS to inject the appropriate drivers to match AWS virtual hardware. Velostrata also offers cloud-bursting features with their software solution and PrimaryIO offers similar capabilities (more on those another time).
The Architect’s View
Obtaining the most benefit from hybrid cloud means removing the barriers on data mobility. There is a rising tide of solutions in the marketplace to move data around, but little so far that visualises where data is sitting and how it is being accessed and protected. The challenge in the future for storage administrators is not in managing the hardware – with the introduction of flash all those old issues of performance management are gone. Instead the focus is on data mobility and protection in an ever distributed world.
Further Reading
You can find more about the presentations at Storage Field Day 9 using the link listed below, including blogs from other delegates.
- SFD7 – Primary Data and Data Virtualisation
- Avere Systems Releases Virtual Edge Filer to Deliver Data to Compute
- Storage Field Day 9 Events page
- NetApp Presents at Storage Field Day 9 (Tech Field Day website, retrieved 30 March 2016)
Copyright (c) 2009-2020 – Post #F07E – Chris M Evans, first published on http://blog.architecting.it, do not reproduce without permission.
Disclaimer: I was personally invited to attend Storage Field Day 9, with the event team covering my travel and accommodation costs. However I was not compensated for my time. I am not required to blog on any content; blog posts are not edited or reviewed by the presenters or the respective companies prior to publication.