
Vendors like to tell us how the transition to NVMe-based storage will dramatically improve performance. In fact, I’ve talked at length myself about the benefits of NVMe technology. However, it helps to have empirical (and independent) evidence to back up the claims of the industry. That’s exactly what a team of researchers from the University of Southern California, San Jose State University and Samsung did in 2015. You can find a link to the paper, entitled “Performance Analysis of NVMe SSDs and their Implication on Real World Databases” here.
Legacy SSD Protocols
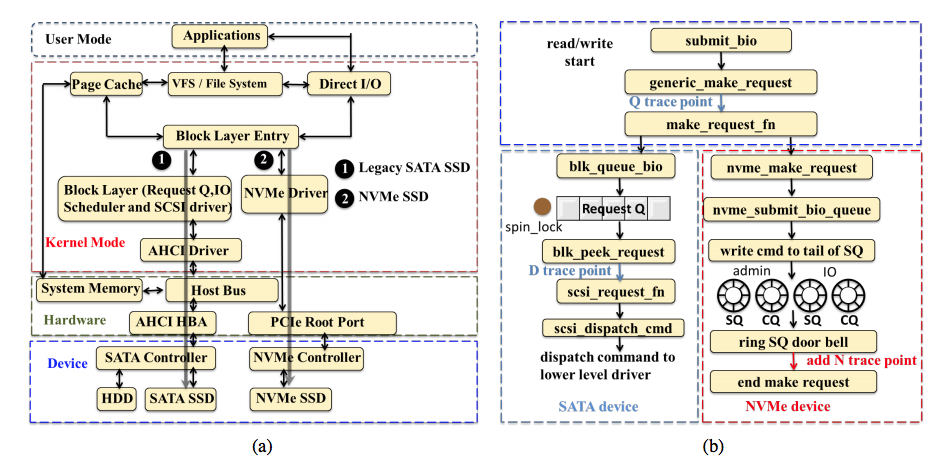
SAS and SATA storage protocols have issues. Both were developed and have derived from technology to connect slow hard drive media. SAS and SATA devices are connected via either HBAs or controllers built into the chipset via the southbridge (see this previous post for details). This hardware interface and the software stack used to support it, represents a significant overhead in I/O processing. This overhead wasn’t obvious when storage devices had performance levels that were measured in milliseconds, however with NAND flash devices (SSDs), the overheads become all too apparent.
By comparison, NVMe was designed to fix many of the issues of legacy SAS/SATA. Physical connectivity is much simplified, with devices connected directly on the PCIe bus (or root complex, to be more accurate). NVMe uses a new signalling process that eliminates the single point of contention in SAS/SATA, namely the “Elevator” request queue. The management of queues in NVMe is handled more co-operatively and I/O processing signalled using a “doorbell” process that significantly reduces CPU overhead. Figure 1 highlights both the differences in the software/hardware stack (a) and the I/O process (b).
Protocol Efficiencies
What do the savings in protocol overhead actually mean? The researchers used fio (an I/O traffic generator) and blktrace (a tool to trace I/O activity) to observe the I/O latency at each point of the traversal of a request from application to device and back again. With blktrace, the I/O time can be divided up to show the time within the application, the O/S kernel, the device driver and the device itself. The results from a low load random read test are shown in figure 2 and take a little deciphering.

The two graphs shown have different scales. On the left are the SATA HDD and SSD comparisons. Hard drive figures are used to provide a baseline comparison. The right-hand graph shows NVMe performance. In absolute terms, the SATA HDD was much slower than the other two devices (14ms compared to 125μs for SATA SSD and 111μs for NVMe SSD). More important, the time spent in software is much lower as a percentage with NVMe. The overhead of NVMe is much lower and so with very low latency storage devices like NAND flash (and of course in the future, Optane) the performance of the storage isn’t compromised by delays in software.
Database Performance
Applying the findings to something more real-world, the researchers moved on to test against both traditional relational and NoSQL databases. MySQL was used for the relational tests and required some additional setup to optimise for NVMe storage. TPC-C testing was then performed against a configuration of a single SSD, four SSDs in a RAID-0 stripe, a single NVMe SSD and a virtual file system in DRAM (tempfs).

The results are displayed in figure 3. Graph (a) shows the results for a single SSD, with the green lines representing a huge amount of CPU wait time. With four drives (b) the I/O load is more distributed so wait time is reduced. With a single NVMe SSD, there is almost no wait time, although the CPU isn’t fully utilised. Similarly in (d), the tempfs control, the user time is higher (representing the improvement in performance/latency from DRAM compared to NVMe), with no discernable wait time at all.
The TPC-C performance figures, relative to a single SSD (1.0) were 1.5 for multiple SATA SSDs, 3.5 for NVMe SSD and 5.0 for DRAM. Further testing for NoSQL databases (Cassandra and MongoDB) yield similar results. As these tests indicate and the report quotes early on; “NVMe drives are never the bottleneck in the system“.
What this paper doesn’t show is how this extra performance is being used by the infrastructure vendors. When the media is no longer the bottleneck, traditional storage architectures will inevitably be wasting I/O bandwidth at the media level. This is why we’ve seen the development of disaggregated architectures like that from E8 Storage and Excelero. We’ve also seen some interesting initial performance figures from the HCI community, as highlighted by Scale Computing and X-IO with Axellio. These distributed architectures remove some of the bottlenecks imposed by channelling I/O through a traditional controller model, with the trade-off that some data services may not be (initially) supported.
NVMe Performance
What can we learn from this paper? It’s clear from the analysis done that NVMe as a protocol shortens and optimises the data path to deliver vastly improved latency and performance over SAS/SATA. As the paper indicates, the benefit of NVMe stems from three things; better hardware interface (the use of PCIe), shorter data paths and a simplified software stack. Random I/O performance figures quoted in the paper bear this out. In 4KB random read tests, a standard SATA HDD achieved 190 IOPS, SATA SSD 70K IOPS and NVMe SSD 750K IOPS. Remember that the SSDs are essentially using the same media with over 10x improvement in performance.
The Architect’s View
Like all-flash before it, the initial use-cases for the high performance offered by NVMe will be limited by the cost/benefit of using the technology. However, we’re on the cusp of an architectural change that will transform some types of workload, like analytics.
One last thing; how is the public cloud taking advantage of NVMe and how are applications being tuned to exploit it? How will the recent Intel CPU bug impact performance compared to say, the additional I/O capabilities of AMD EPYC processors? Perhaps the public cloud isn’t as hardware abstracted as we like to think…
Further Reading
- ‘Kernel memory leaking’ Intel processor design flaw forces Linux, Windows redesign (The Register, retrieved 3 January 2018)
- Axellio Edge Computing Systems (X-IO website, retrieved 3 January 2018)
- Scale Computing Announces Hyperconvergence with NVMe for Unprecedented Performance (Scale Computing website, retrieved 3 January 2018)
- Storage Field Day 14 Preview: E8 Storage
- What Next for the new Tier 0 Storage?
- Garbage Collection #005 – Disaggregated Storage (Storage Unpacked, retrieved 3 January 2018)
- Disaggregated Storage Part II with Zivan Ori from E8 Storage (Storage Unpacked, retrieved 3 January 2018)
- Disaggregated Storage Part III with Josh Goldenhar from Excelero (Storage Unpacked, retrieved 3 January 2018)
Comments are always welcome; please read our Comments Policy. If you have any related links of interest, please feel free to add them as a comment for consideration. Copyright (c) 2007-2019 – Post #05CE – Chris M Evans, first published on https://www.architecting.it/blog, do not reproduce without permission.