
In recent blog posts, we’ve discussed the benefits of a hybrid cloud storage strategy as a way of improving the end-user experience, mitigating supply chain issues, and adding agility to the business. In this post, we look a bit deeper into how the on-premises and public cloud technologies align to build a hybrid cloud strategy.
This work has been supported by NetApp, so we will use Amazon FSx for NetApp ONTAP as our example platform in comparison to NetApp ONTAP for on-premises storage.
Background

In this post published in May 2022, we looked at why businesses should be implementing a hybrid cloud storage strategy. It’s clear from the discussion that both on-premises and cloud have differences in implementation and experience. The infographic shown in figure 1 (click for a full-size version) provides some idea of those differences. From a standing start, ordering, installing, and consuming on-premises storage has a longer “time to value” and different experience for both the administrator and end user. There’s also a very different TCO model involved across both options, including a classic Capex vs Opex alignment to achieve.
However, at the same time, the end-user experience needs to deliver the same result – whether on-premises or in the public cloud, the user simply wants storage to attach to an application.
Diversity
Unfortunately, as anyone using multiple public clouds will know, the process of deploying storage and applications across the public cloud vendors is very different. AWS, for example, has EBS and local NVMe devices for block storage, plus EFS and FSx for file systems. Then there’s the de facto S3 for object storage.
Azure has Disk Storage for block protocols, Azure Files and Azure NetApp Files for file storage and Azure Blob Storage for object (not S3 compatible). GCP has Persistent Disk, Local SSD, Filestore (Basic, Enterprise & High Scale) and Cloud Storage that align with the block, file, and object protocols.
Although the offerings from each platform sound similar, they’re implemented and operated in vastly different ways. For example, there is no standardisation in APIs, the performance of each solution will be different, security models are different, and so is pricing, where things can be very complicated and essentially impossible to compare between vendors. While we wouldn’t say vendors are deliberately obfuscating services to make comparisons difficult, the evolution, need to differentiate, and the skill set of the platform designers means there is no common experience across the public cloud.
Alignment
It’s unlikely that many businesses want to make direct comparisons across clouds. Where multiple public clouds are in use, the different experiences across each platform are, unfortunately, a fact of life. Some of the cross-platform challenges can be mitigated with tools that essentially add a shim onto the APIs of the cloud providers. While this approach can work, we now have another layer of indirection and another platform for which dependencies, upgrades and management must be performed.
Dependencies in this scenario are a particularly troublesome issue. The abstraction or shim layer provides the capability to support the underlying APIs, but when these change, the shim component will need to be updated. If this vendor is slow to act, then the customer can’t take advantage of new features. Every aspect of difference in implementation models also introduces risk, such as failing to align the security model across clouds, for example, because some implementation detail wasn’t fully understood.
The End User
Starting with the end user, how should the process, or experience, be standardised? Internal business units within an organisation want to:
- Consume storage resources through a consistent set of endpoints. This generally refers to object or file storage as block storage is much more closely integrated with the platform and not exposed to the outside world; more on this in a moment. An endpoint definition should ideally be an abstracted DNS name rather than a physical device or IP address. This allows for data mobility and minimises the impact of embedded URLs in documents.
- Define requirements based on hardware abstracted concepts like IOPS, bandwidth and latency. Users don’t need to care about the implementation details of storage, instead are focused on what’s required for the application. These metrics are quality of service (QoS) definitions for storage that may need to be dialled up or down over time.
- Define expected capacity usage. While scalability in the public cloud is effectively unlimited, budgets are not. This means quotas need to be set, just as on-premises systems do.
- Ensure data is protected and recoverable. Data protection must be an integral part of any storage offering. Users should also be given a choice of levels of protection (determined by cost). This includes both availability (e.g., replication) and regular backups.
- Simple pricing. End users need clarity on pricing, which should be based on capacity consumed across each tier of performance. Data protection should and will attract an additional charge based on capacity protected and frequency of backups. Many businesses choose to use showback rather than chargeback. This isn’t a problem in the public cloud, as long as someone eventually pays the bill.
None of the above requirements is difficult to achieve, and for decades, businesses have been offering internal customers exactly these services through service catalogues. How does this translate to the public cloud?
FSx for ONTAP
AWS announced the general availability of Amazon FSx for NetApp ONTAP back in September 2021. The “FSx” solutions are “extensions” to the standard file system offering in AWS, known as Elastic File System. We’ve put the “extensions” in quotes because the FSx family are separate products that implement a range of existing file system solutions as services in AWS and therefore are distinct from EFS. These now include Amazon FSx for NetApp ONTAP, OpenZFS, Windows File Server and Lustre.
Each offering is fully managed by AWS and natively integrated into the AWS platform. This means the customer gets APIs, integration with the AWS security model, networking, storage, monitoring and more.
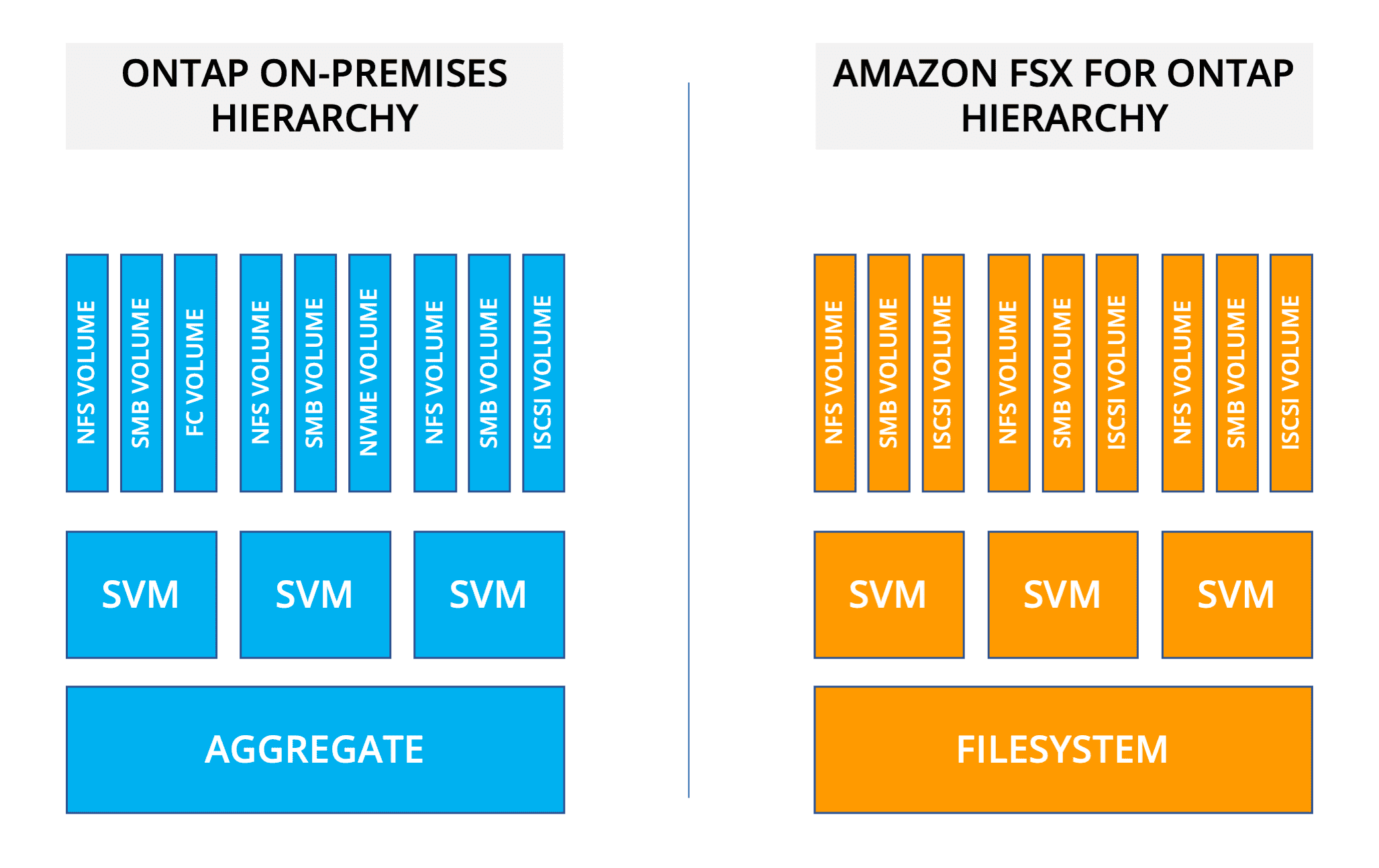
The implementation of FSx for ONTAP closely follows the on-premises implementation of ONTAP. Both have a baseline of storage from which volumes are provisioned. Both allow for multi-tenant namespaces through storage virtual machines. Figure 2 shows the hierarchy of entities from storage upwards. Note that on-premises implementations support additional protocols – Fibre Channel and NVMe – that aren’t available in FSx for ONTAP. However, block storage is available through iSCSI for applications that need block access.
Access

In FSx for ONTAP, each volume has a unique ARN (Amazon Resource Name), as do SVMs, making them accessible through AWS CLI and API calls. Attaching a volume is as simple as mounting the NFS share or connecting to an SVM mapped through Active Directory (see Figure 3). So, the user has the same experience on-premises as in the public cloud; map to an NFS or SMB share or use iSCSI for block devices. Data protection is automatically integrated and enabled by default, although currently, this encompasses only a single daily backup.
Earlier, we discussed the concept of a storage catalogue. In FSx for ONTAP terms, performance capabilities are set at the file system level. This means an administrator must create separate file systems to implement single versus multi-AZ support or to increase the provisioned IOPS capability. File systems are also used to determine encryption key settings, storage efficiency features and tiering pool policies. Figure 4 shows how the administrator can use the quick options or go into detail to specify each parameter manually.
Now we have reached an interesting point in our discussion. Precisely how should administrator tasks be managed in the public cloud, compared to on-premises?
Administrator Roles
The traditional role of the on-premises storage administrator includes the provisioning, deployment, support, maintenance, and management of physical hardware. This role also encompasses the administration of resources given out to users.

In the public cloud, none of the former tasks applies (see figure5). The administration role is vastly simplified, as (in our example) AWS provides all the backend provisioning, management, and maintenance of the infrastructure. The storage administrator now has time to focus on standards, security, and data management tasks. But is an administrator actually needed for the public cloud, with such a simple consumption model as FSx for ONTAP?
We believe that in a hybrid environment the storage administrator still adds value. Someone needs to align the performance requirements and capabilities of on-premises storage to those in the cloud. Storage consumption and capacity growth still need to be monitored in the public cloud, while baseline file systems will need to grow and be extended. We could argue that other file system solutions don’t require the same degree of management or configuration as FSx for ONTAP. But in AWS at least, EFS does not support SMB, FSx for Windows File Server doesn’t support NFS. FSx for ONTAP supports both protocols and enables customers to replicate data to and from on-premises to the public cloud using NetApp SnapMirror, a highly efficient replication tool. Businesses gain significant operational advantages using FSx for ONTAP for a small amount of additional management.
Administration Tasks
For the administrator, the following tasks align across both on-premises and public cloud.
- Logical infrastructure design. Determining the performance and throughput characteristics of systems, designing multi-tenancy with SVMs, mapping SVMs to the networking configuration, implementing the security model. Applying data efficiency rules.
- Data Protection. Implementing data protection policies, monitoring backup success and failure.
- Capacity Management. Ensuring sufficient resources are in place for long-term growth and short-term demand.
- Cost Management. Using usage data to assign charges to internal customers and lines of business or providing showback data on consumption.
- Data Mobility. Implementing SnapMirror to move data between on-premises and the public cloud (or even within public clouds).
Most of these tasks are data, rather than infrastructure-focused. Modern infrastructure needs much less handholding than the solutions deployed one or two decades ago. The positive outcome of this is that businesses can now choose to use three options when deploying storage infrastructure:
- Self-service – deploy and manage everything on-premises
- As-a-Service – offload hardware management tasks to the vendor for on-premises
- Public Cloud – use the public cloud to augment or replace on-premises.

The administrator is gradually changing roles to one of gatekeeper rather than being an operational dependency.
The Architect’s View®
Reading back this post, on reflection, it might seem that using technology such as FSx for ONTAP is merely moving “legacy” on-premises technology to the cloud and transferring the overheads with it. That view couldn’t be further from the truth. The public cloud has enabled businesses to dispense with hardware management while focusing on the critical value in the business – data and applications – but data management is still necessary.
The standardisation offered by FSx for ONTAP enables businesses to leverage existing data resources and data management practices. For example, AWS recently announced VMware Cloud on AWS integration with Amazon FSx for NetApp ONTAP as an external, supplemental NFS datastore. Customers can now replicate data from on-premises to the cloud using efficient features such as SnapMirror. Businesses can now easily move data from existing on-premises infrastructure into the public cloud – and back again – and, with that capability, implement true data and application mobility.
There’s so much more detail in the Amazon FSx for NetApp ONTAP service than we can discuss in this blog post. However, what’s clear is the capability to create a unified, standardised data layer that spans on-premises and the public cloud makes it infinitely easier to deliver the flexibility of a hybrid cloud. We recommend checking out the following additional content, which builds on the concepts in this blog post.
Copyright (c) 2007-2022 – Post #faaa – Brookend Ltd, first published on https://www.architecting.it/blog, do not reproduce without permission.