
When so many businesses are totally dependent on their digital information, data protection becomes a key requirement for every IT organisation. The way in which we implement technology changes almost daily and this affects the choices on how we protect it.
Where 20 years ago the standard model for deployment was based on physical servers, today we have almost ubiquitous server virtualisation, hyper-converged infrastructure and the emergence of containers.
Applications have become more mobile and the dependence on storage appliances or arrays no longer exists. Hyper-converged infrastructure (HCI) is changing the financial model for businesses to the extent that end users can almost plug and play new hardware, then allow applications and data to automatically distribute themselves over the available infrastructure.
This change in deployment process also affects the operational model for IT. Server virtualisation abstracted the server, making traditional backup more difficult to deploy. Because of this, we’ve seen the evolution of APIs that integrate directly with the hypervisor (more on this in a moment). HCI pushes this model even further, with no shared storage on which to offload the backup process.
The result is a need to change the way backup is perceived and implemented in modern IT deployments.
Traditional Backup

Why is traditional backup so inappropriate for modern IT? Let’s look at exactly how things used to be done. Before server virtualisation, applications were deployed on individual servers. It was typical to deploy one application per server, especially on Microsoft Windows, due to issues like DLL dependencies. Technology was also generally paid for on a project basis, so businesses liked to run only their application on hardware they paid for.
With this architecture, each host was provided with plenty of bandwidth. Larger organisations could afford and would deploy dedicated backup networks, with agents on each server used to track changed data. At the centre of it all was the backup platform. More scalable backup systems divided hardware into metadata/scheduling and media servers. During backup, each host would funnel data to a media server, with the metadata server tracking which files had been backed up.
Pinch Points
Typical pinch points for the backup administrator would be in getting enough data on the network to keep the media servers busy, while at the same time being able to write the data efficiently to either tape or a disk archive. As primary data volumes grew, invariably the backup architecture would need reworking, either incrementally or through an entire redesign. Depending on the level of data growth, this backup reorganisation could occur quite frequently. Many IT organisations couldn’t cope with this degree of change and would simply deploy a new backup platform, resulting in sprawl and significant increases in management overhead.
Virtual Backup
As the world moved to server virtualisation, traditional backup became a problem. Virtualisation was introduced to save hardware resources, so where previously each application/host had dedicated networking and storage, now those resources became shared. Consolidation created the illusion of each application having a dedicated server, but in reality, the amount of physical hardware was drastically reduced.
The typical data path for backup was now changed. The concept of a backup network was impractical to implement because so many virtual machines could be deployed on a single server, making it impossible to dedicate network resources. Instead, the hypervisor vendors introduced APIs that provided direct access initially to make snapshots of virtual machines, then over time to provide access to a stream of changed data for each VM. With the use of VM guest agents, backups could be taken that were application consistent and optimised to only extract changed blocks, rather than entire changed files.
External Storage
Some vendors have introduced interoperability with external storage arrays, allowing the array to do the heavy lifting of taking an application snapshot that is then fed via the same API to the backup platform. To work efficiently this kind of process requires that the application in question is deployed on individual volumes, or significant amounts of additional snapshot data will be retained. HCI Backup

As we move to the HCI model, virtualisation changes again. Server virtualisation typically used shared storage in the form of a storage appliance and storage area network. The “SAN” offloads a lot of the heavy lifting that has now been incorporated back into the server. This is an important consideration as we look at the data path for backup with HCI.
HCI generally uses two models to implement the features of shared storage. Either the services are implemented as part of the hypervisor kernel (like VMware Virtual SAN) or they are delivered within a virtual machine (like Nutanix). In the kernel model, the hypervisor is the data mover, feeding data to the backup application. In the VM model, the storage virtual machine (SVM) is the data mover. It’s easy to see that the bottleneck in HCI backups can quickly become the SVM, which has to have sufficient resources to funnel data to the backup software in a timely fashion.
The question for HCI deployments is in where the backup application should reside. With server virtualisation, it was typical to retain separate hardware for this function. With HCI, one of the aims of the architecture is to consolidate as many applications as possible onto the single shared platform, which means running backup on the same infrastructure as the applications.
Backup as Software
In an HCI world, where a single platform is both the place to run the application and store data, how should backup be implemented? The most obvious answer is that backup is simply another application on the platform. This means the backup service runs as a virtual machine and moves data from the hypervisor to a backup target.
To be 100% certain that data is protected in the case of hardware failure, the target for backup needs to be another device separate both physically and geographically distant from the HCI platform. This might be another HCI cluster located elsewhere, or a storage resource such as an NFS server or object store.
The target could even be the public cloud, although having public cloud as the only target is likely to make it difficult to meet service level objectives for recovery if a large amount of data needs to be restored. A good compromise is to stage data backups to the public cloud as they age and are less likely to be used.
Metadata
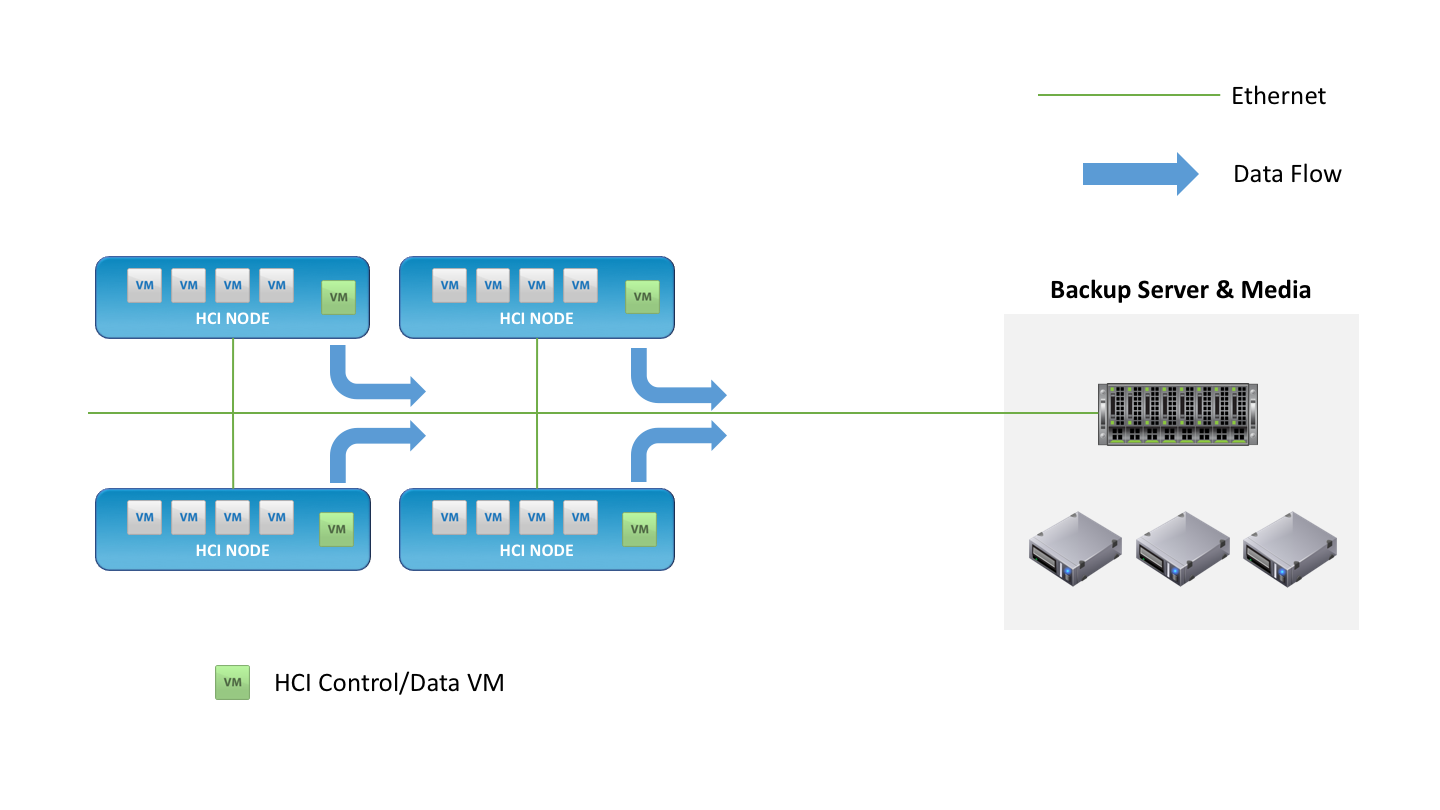
A fundamental requirement of any data protection system is the metadata describing what has been backed up. When backup runs on the same physical platform as the applications themselves, it is essential to get a copy of that metadata off the HCI platform and in a place from where it can be recovered if the HCI platform is lost.
There are two ways to achieve this requirement. Either the backup data becomes self-describing and incorporates the metadata, or the metadata itself is backed up and stored off-platform. Exactly how this is achieved depends on the backup solution, but it makes sense to ensure the process of recovering the metadata is as simple as possible because this scenario usually happens when there is a bigger crisis in play.
Benefits of HCI-Focused Backup
What if backup was designed specifically to work with HCI? To achieve this, the backup software would need tight integration with the HCI platform itself. This means:
- Automatic identification and protection of virtual machines/instances, once given backup platform credentials.
- Integration with platform-specific APIs to extract and backup data. Integration also needs to manage snapshots and pausing applications for consistent backups.
- Scalability within the backup application/instance to cater for increased load as deployments increase.
- Licensing that mirrors the platform deployment model, for example, per-VM or instance charging.
- Self-protection of the backup VM, to be able to restore the entire environment in case of hardware failure.
- Multi-tenancy – allowing multiple backup environments to back up segments of workload on demand.
- Scripted or automatic deployment of the backup solution onto the HCI platform.
Most of these requirements are self-evident and mirror what has been done for server virtualisation platforms. However, the last two are perhaps a little different. If backup is to be truly aligned to an HCI model, then this should include the nature of the way in which workloads can be added or removed from an HCI platform.
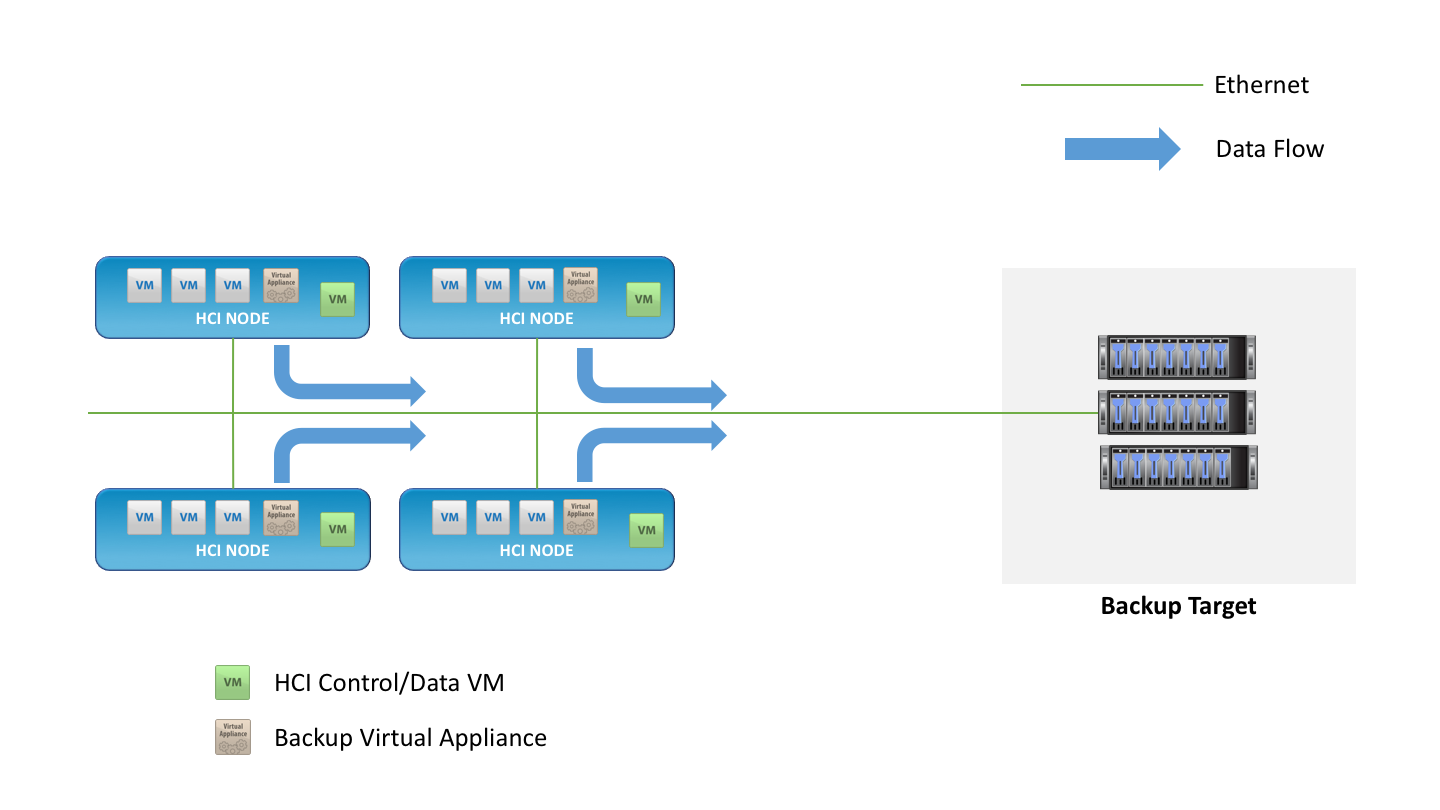
HCI allows a high degree of application deployment automation via API and CLI. The platform is there to be consumed, which can be achieved without the intervention of an administrator. Why shouldn’t backup be the same? Imagine a new project that will run a few dozen virtual instances for a few months. If this is a development project, it makes sense to keep backups separate from production, write the backup data to a dedicated target and isolate the backups for future use.
The last point – automation – speaks exactly to this requirement. Backup becomes another service that can be deployed and configured on-demand to meet the needs of the end user. The most logical conclusion of this being the addition of backup to a service catalogue accessible by end users.
HYCU
HYCU is a backup solution from HYCU Inc, a company with a long heritage of developing backup software solutions and now operationally independent from the Comtrade Group. Version 3.0 of the HYCU backup platform was recently released, adding additional support for Nutanix HCI solutions as well as native support for VMware vSphere ESXi.
HYCU is deployed as software and can be spun up as a virtual machine instance within minutes. Administrators simply need to provide credentials to the HCI platform, from where HYCU can identify and immediately start backing up virtual machines. Licensing is configured on a per-VM or socket basis, making it easy to align operational costs to business demand and service catalogues.
Uniquely, version 3.0 now supports the Acropolis File System (AFS) on Nutanix. To meet the needs of modern HCI, HYCU can be administered via REST API, providing the capabilities of automation. More details on HYCU, both the company and software can be found on their website, www.hycu.com. We will be covering installation and automated build of the HYCU platform in future posts.
The Architect’s View
We continue to see evolutions in backup and data protection. At the end of the day, protecting data is just another function that could easily be delivered as a virtual appliance or application. Expect backup vendors to provide more focus on the process, the metadata and the content than on hardware specifications and physical deployments. This of course, includes making backup data self-describing and portable, because the choice of hypervisor today could be a different one tomorrow.
Comments are always welcome; please read our Comments Policy. If you have any related links of interest, please feel free to add them as a comment for consideration.
Copyright (c) 2007-2019 – Post #4EC8 – Brookend Ltd, first published on https://www.architecting.it/blog, do not reproduce without permission. Photo credit iStock.
Disclaimer: HYCU, Inc is a client of Brookend Ltd.