
As cloud platforms continue to expand, we look at some of the native data protection options for Google Cloud, including what we should expect from mature ecosystems supporting enterprise applications and how that compares to what’s actually available.
Background
Although Google has offered cloud-like services for many years, the central components of what is now called Google Cloud Platform have only been available for about the last decade. The Compute Engine, for example, was launched in preview in 2012, with GA the following year. Since then, the application landscape has expanded significantly, with similar growth in physical data centres (zones) worldwide. Although generally considered to be in third place behind AWS and Azure (based on adoption numbers), GCP is a mature platform with many service offerings focused on data.
Data Protection
Regardless of location, all applications used by a business will require some degree of data protection, typically in the form of backup. We don’t need to go over the reasons for protecting data in this discussion, but just be mindful that both data and application frameworks need to be covered. Cloud backup is the user’s responsibility, even when using natively integrated tools.
Services
GCP (by its own admission) offers over 100 products or services, divided into traditional groupings like Compute, Databases and Storage. Although not an exhaustive list, we’ve attempted to summarise the major offerings in the diagram shown.
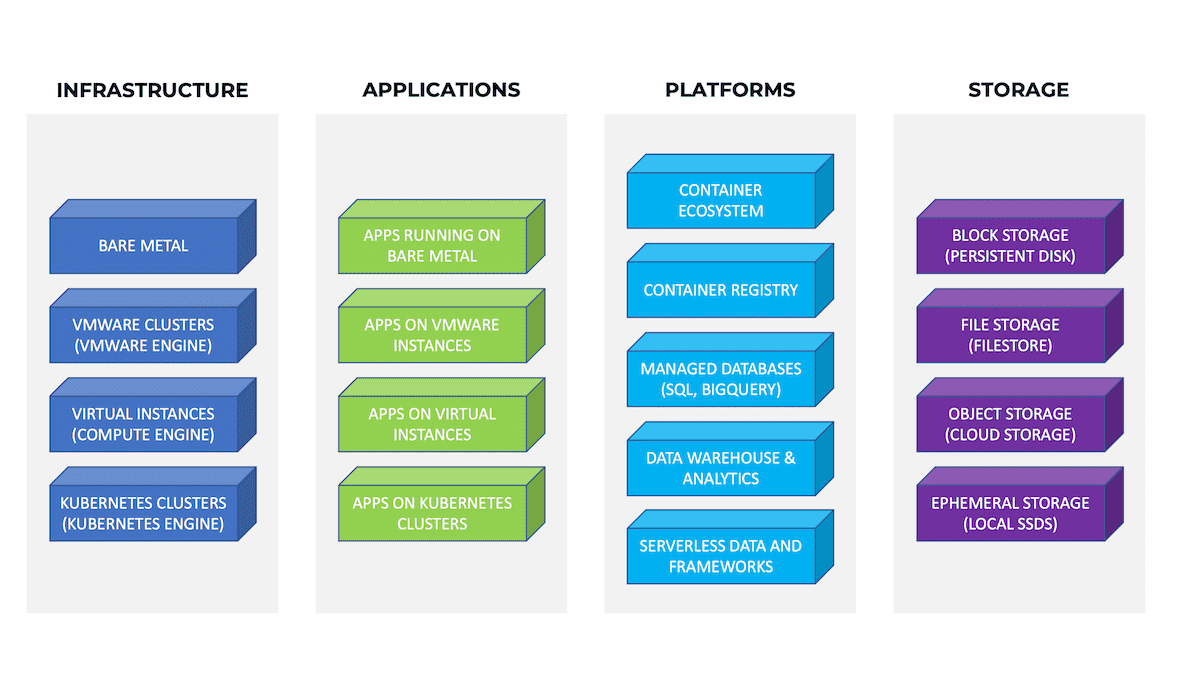
Coverage
When choosing how to protect data, there’s the option to simply snapshot entire virtual instances or focus on the data itself and take application-specific backups. In general, complete data protection will mean taking backups in both formats, albeit for different retention periods. For example, an application database running in a VM could be protected with daily snapshots for rapid recovery, with an application-based backup to mitigate against crash-copy recovery and provide transactional-level granularity.
Choices
Enterprise-class backup also demands portability, long-term retention, granularity, and efficiency, amongst other features. It’s clear from our diagram that there are many data points to protect within GCP. Let’s look at some of these in more detail and see what’s available within the platform.
Compute Engine – native backups are implemented through snapshots of persistent disks. This is a common approach in the public cloud. GCP offers the capability to take application-consistent snapshots, by which they mean operating system consistent, where I/O is flushed to disk before the snapshot is taken. Snapshots can be regional or multi-regional, replicating to another continent (the US, Asia or EU, in GCP terms).
The snapshots approach represents several immediate challenges.
- Snapshot restores require recovery of the entire snapshot by creating a new disk then attaching the new disk somewhere to recover the content. This is fine if the intention is to recover the whole disk (such as a boot disk) but wasteful and time-consuming for other data.
- There is no indexing within GCP for the content of a snapshot, making it challenging to locate and recover files without knowing the file structure of the original source (or performing lots of restores).
- Snapshots are independently taken for each disk, with no capability to create “consistency groups” where multiple disks are taken as a single atomic snapshot. This makes file systems spread across multiple disks unsuitable for snapshots.
- Snapshots are locked to the GCP platform and cannot be moved to another provider. As a result, they don’t represent a good long-term backup solution, merely a recovery mechanism for applications in virtual instances while they run in GCP.
So, while they have a purpose, snapshots are also sub-optimal as a long-term data protection strategy. Bear in mind that there is no native application data protection for any application within a virtual instance. That’s down to the user to implement.
Kubernetes Engine – let’s look next at the ability to protect Kubernetes-based applications. First, we should remember that a GKE cluster is simply a series of virtual instances running in Compute Engine. So, the same snapshot ability applies to GKE instances like any other regular instance. GKE also offers an integrated backup service, which runs within a cluster.
There are a few prerequisites to configure (like Workload Identity and enabling metadata services) after creating a GKE cluster. Once these are done, Backup for GKE can be enabled, currently in preview/beta mode only. This isn’t a production service yet. From here, it’s possible to define a backup plan for each cluster, targeting the output to a GCP region. The challenges of protecting GKE include:
- Snapshots aren’t an adequate protection method, as a restore of one node in a cluster will be inconsistent, and any entire cluster restore will affect all applications. We can discount the idea of snapshots for GKE protection.
- When using Backup for GKE, the data target is an obfuscated location managed by Google. There’s no transparency into exactly where the data is stored. So any restores are only targeted at another GKE cluster.
- Backup for GKE doesn’t offer the ability to search backups to determine what applications have been backed up. This can make it tricky to locate clusters and namespaces without having implemented a strong naming policy.
- Restores require a target backup plan – which are deleted when a cluster is deleted. The restore process for a deleted cluster therefore requires the end-user to create a cluster, create a backup plan, associate the restore plan with the backup plan – all before executing the restore process.
On a positive note, backup plans can be specified at the namespace level, making it possible to back up individual applications deployed in unique namespaces. The current implementation of Backup for GKE looks like a temporary solution for developers to protect their test environments rather than something enterprise-class.
VMware Engine – we haven’t evaluated the VMware Engine offering; however, the documentation indicates that customers should use whatever backup protection method was in place for on-premises deployments. This essentially means using a third-party solution that offers vSphere integration.
Managed Databases – We looked at data protection offerings for managed SQL. GCP provides a native capability, which helpfully takes an initial backup after the creation of a SQL instance. Automated backups sit within a user-configurable 4-hour backup window, with a default of 7 automatic backups and 7 days of logs. The target of backups can be another region, which could be quite helpful. Unfortunately, a restore is an entire restore of the whole instance, although backups are incremental.
- An application-focused backup inventory
- Application-focused Backups
- Managed Databases Require Managed Backup
Possibly the most significant challenge for database administrators is the inability to restore to unlike database versions. This may seem an obvious restriction. However, imagine a scenario where GCP deprecates a database release. All historical backups become unusable. Of course, this problem may not be an issue for any user, as all backups are deleted when an instance is deleted. This restriction poses an issue if databases are routinely moved between managed instances.
Actifio GO
Back in December 2020, Google acquired Actifio, a “start-up” vendor of data protection solutions. I put the term in quotes as the company was initially founded in 2009, and over the 11 years as a private company took in around $352 million in investments. A reverse stock split in October 2020 arguably made the company more attractive to acquisition but erased any value for existing shareholders.

Logic says that Actifio’s data protection solutions should now be nicely integrated into GCP and be in the prime position to centralise all backups and backup data. Unfortunately, this isn’t the case. We decided to try out Actifio and followed the installation process, as documented in the Actifio GO Deployment Guide. The steps involved are similar to most marketplace solutions, which require the assignment of roles to the Actifio Sky management plane and some peering networking definitions. The solution next deploys a data mover in the customer GCP project. After a few hours of running through the installation (including in-place upgrades), we abandoned the test and never completed the process.
The Architect’s View™

As we can see from this brief review, the collection of data protection features in GCP feels very disjointed, with no overarching strategy. Each platform implements a slightly different point solution that doesn’t fulfil the standard requirements expected from data protection. Actifio GO falls at the first hurdle. The solution isn’t integrated into GCP and looks both dated and antiquated compared to other solutions we’ve run in GCP (like HYCU). We couldn’t recommend using Actifio GO to protect any GCP workloads.
The obvious lesson from this quick review is that Google Cloud users will find more benefits using partner organisations for data protection. We’ve already discussed this stance through the demonstration of HYCU for Kubernetes in this blog post. We run HYCU as our primary backup solution for production workloads in GCP using a paid-for account, so we can validate the solution works at an enterprise level. Other vendors are, of course, also available.
Data protection is an obvious service offering for the public cloud, but as we’ve seen, GCP has some way to go with native protection. We’d prefer to see Google and the other cloud hyper-scalers provide improved APIs to ensure data can be safely extracted from applications running on bare metal, virtual instances, containers or on generic storage. With decent APIs in place, businesses can standardise on data protection that doesn’t provide lock-in to a single platform that also works cross-platform – both SaaS and IaaS. This view isn’t limited to GCP; abstraction from dependency on any one cloud data protection solution is our recommended strategy and one we follow ourselves.
If you’re looking to build out a data protection strategy for the public cloud, be aware that the implementation of backup is still your responsibility. It’s better to own the data, primary or secondary because even backup data is a valuable company asset.
Copyright (c) 2007-2022 – Post #b8ea – Brookend Ltd, first published on https://www.architecting.it/blog, do not reproduce without permission.