
This post is one of a series of previews of companies presenting at Cloud Field Day 3, an invitation-only event in Silicon Valley, taking place 4-6 April 2018. For more information, see the dedicated CFD3 events page https://blog.architecting.it/events/cloud-field-day-3/.
We all love backup, right? OK, it may not be top of everyone’s wish list, but data protection is important, if not always valued (see my Rubrik pre-event post). Data protection has changed over the years from a function that needs to be done but wasn’t always rigorously implemented, to one that can now have direct implications on the operation of every business.
Getting backups to work effectively is hard for a number of reasons. The volume of data created continues to increase at eye-watering rates. At the same time, enterprise computing has started to break out of the data centre. Add to the mix a little staff optimisation and focus on cost reduction and the result is a need for a different way of protecting data.
Druva
{kind=link}
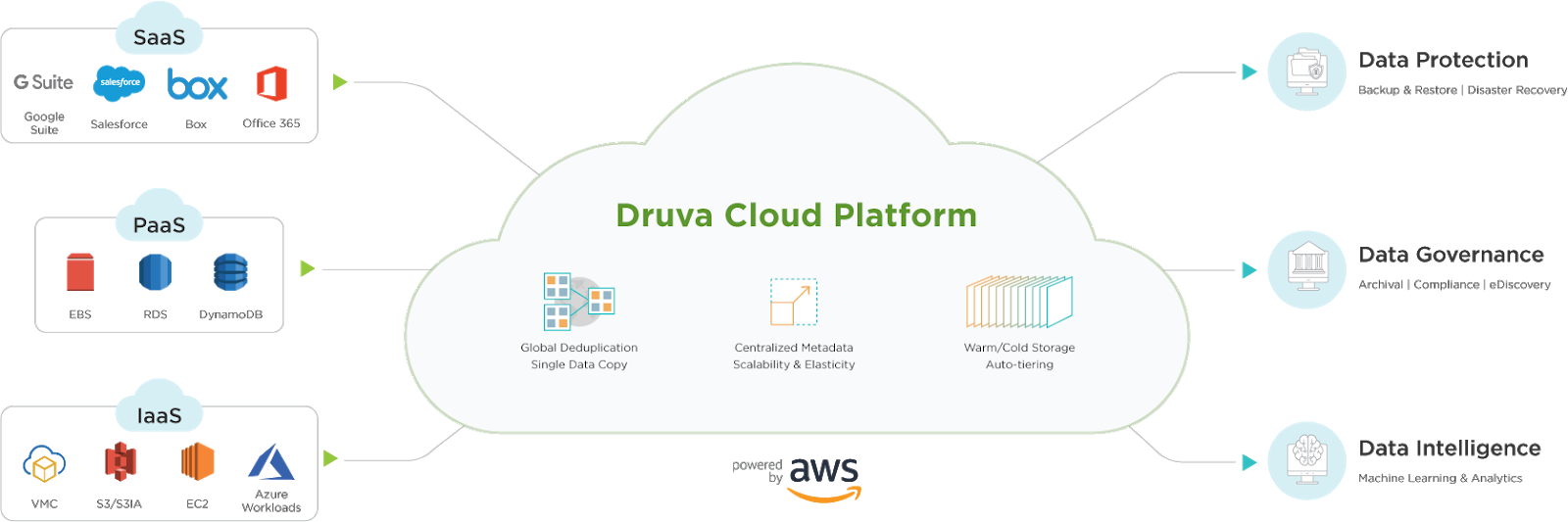
This is the message Druva would like us to focus on – that the IT world is more diverse and dispersed than ever before. The company began as an endpoint protection start-up. By that we mean laptops and PCs sitting in the enterprise. So the roots of dealing with a distributed environment were already there. In 2014 Druva decided to pivot a little and move into data protection for enterprise applications. Today, the Druva Cloud Platform delivers backup for the enterprise, now protecting Iaas, PaaS and SaaS applications. Implementation of data protection is divided into three products.
- inSync – protection for end-user data
- Phoenix – enterprise infrastructure (both virtual and physical)
- CloudRanger – data protection for cloud-native workloads
Extending the data management paradigm, each of these services in the Druva Cloud Platform now does not only data protection but offer governance (archival, compliance, eDiscovery/search) and intelligence (analytics functionality).
Detail Matters
Of course, the specific detail of how these services are delivered purely from public cloud is interesting to us infrastructure-focused folk. The Druva platforms were designed and built for public cloud and that has some distinct benefits and disadvantages. For example, scaling is much easier in a platform like AWS, compared to deploying on-premises physical backup infrastructure or appliances.
Note that virtual appliances may be the exception here, but that’s a separate discussion. However, if all of your data is in a single data centre, then the size of the pipe between your servers and AWS needs to be huge and this could have an impact on both performance and the cost of implementing a solution.
Getting into the detail of how the service is delivered will be a key section of the Druva presentations. Exactly how are the services implemented and how does scaling work? How does this translate to the cost profile of data protection? Can I work cross-cloud, cross-region and how easy is it to move my backup metadata between platforms – or even back onsite?
The Architect’s View
Moving data protection to the cloud is a great idea, purely from an infrastructure management perspective. Designing, building and supporting backup systems is hard work and that’s one of the reasons why appliances like those sold by Commvault, Rubrik and Cohesity have such appeal.
However, the real value is in the data itself. When your product becomes described as a “Cloud Platform”, customers will expect to see data mobility and independence from specific packaging (physical/containers/VMs) and the capability to treat data as a single entity across all instantiations, when performing tasks like search. This is where the cloud comes into its own.
With the introduction of IoT, data may sit at “the edge” and never be fully moved back to a core data centre. In this instance, making backup cloud-native provides the final step in decoupling data from customer-owned large warehouses full of noisy servers. Druva’s direction has promise; I’m looking forward to seeing how that evolution has progressed.
Comments are always welcome; please read our Comments Policy first. If you have any related links of interest, please feel free to add them as a comment for consideration.
Copyright (c) 2007-2019 – Post #DC48 – Chris M Evans, first published on http://www.architecting.it/blog, do not reproduce without permission.