
In a previous post on Kubernetes storage benchmarking, we looked at why measuring performance is important. In this post, we look at how to run a benchmark test that provides an equitable and fair comparison between container-attached storage solutions.
Tools
To successfully benchmark any storage solution, we need to simulate an application workload and measure the results. We can do this on two levels. The first is to run tests directly against storage volumes, and the second is to generate load on a typical application like a database.
Load testing volumes is a relatively simple process, and free tools are readily available across multiple operating systems. Iometer (originally developed by Intel) has been a perennial favourite for Windows testing (a Linux version is also available). However, the project hasn’t been updated since 2014. An alternative is fio (Flexible I/O Tester), written originally by Jens Axboe and widely available for Linux distributions with frequent updates. There is also limited support in fio for Windows via Cygwin.
Both fio and iometer test block-based storage (although fio does expect to see a file system directory). Other solutions such as dbench are suitable for testing network storage performance, including NFS, SMB and iSCSI, although that’s not part of the discussion here, as we’re focused on testing storage attached locally to a container.
At the database layer, we can test using solutions like HammerDB, sqlbench or pgbench. These tools generate transactional load that will show performance results proportional to the speed of the platform, amount of DRAM and speed of storage. We won’t cover these today but will leave for another time.
Profiles
As we discussed in the previous post, vendors like to test with a variety of I/O profiles. These are typically based on sequential and random I/O, read/write (separately and combined), plus a range of block sizes.
In a recent set of benchmark tests, we used the fio tool to generate a range of workload scenarios then measure the results. The testing was based on multiple configuration scenarios documented in this dbench project (not to get confused with the dbench reference above). You can find a modification of the dbench script here – perfraw.sh – with some changes we’ll discuss in a moment.
The script uses five profile types:
- Read/write IOPS – a measure of performance capability using 4KB block size.
- Read/write bandwidth – a measure of throughput using 128KB block size.
- Read/write latency – a measure of I/O response time with 4KB block size.
- Read/Write Sequential – a measure of throughput with 1MB block size.
- Read/write Mixed – a 75%/25% split of I/O with 4KB block size.
With each test, the I/O queue depth is varied using a value of 4 with IOPS and latency tests and 16 with the remaining tests. Queue depth is varied to put load pressure onto media and systems to see how well solutions cope with a backlog of work. This process is important for sequential I/O but less relevant for random I/O, where requests have to be processed in order.

Essential Features of Container-Attached Storage 2021 – eBook
 Container-attached storage (CAS) has emerged as a new way to provide container-native storage to containerised and specifically, Kubernetes-based applications. CAS solutions integrate directly into a Kubernetes cluster and offer …
Container-attached storage (CAS) has emerged as a new way to provide container-native storage to containerised and specifically, Kubernetes-based applications. CAS solutions integrate directly into a Kubernetes cluster and offer …
A 4KB block size is common to both file systems and storage devices, but we could choose to vary any of these parameters and run a range of tests across multiple block sizes and I/O queue depths. Running tests across a spectrum of values would show how devices and systems perform across various scenarios, but these still need to be reflective of real-world applications.
Biases
If we were testing physical storage media, then running the above tests against a set of hard drives or SSDs would make a fair comparison. In general, the performance of one SSD over another isn’t going to be affected by the power of the system running the test. The server just needs to have the ability to run enough I/O load without becoming CPU or DRAM bottlenecked.
However, in container-attached storage, we’re testing against software that looks more like a storage system. As a result, the way in which those solutions use local resources will have an impact on test results.
For example, most CAS solutions will cache I/O in DRAM, with a significant impact on test scripts that run multiple consecutive testing steps using the same seed data. The impact of caching results in I/O being served from DRAM without a physical I/O occurring.

Look at figure 1, which shows a time-based graph (X-axis in seconds) and read I/O performance. The blue and orange lines indicate virtual reads (the CAS platform virtual device mapped to a container) versus the underlying hardware (the blue line, in this case, an NVMe SSD). In this scenario, once the data is seeded at the beginning of the test, almost all of the I/O is served out of DRAM, with impressive results. Compare this to figure 2, which shows a write I/O test where the O/S cache was purged every second, forcing the CAS platform to revert to the physical storage and not take advantage of caching and lazy writing.

So, is caching bad? Definitely not. But in real-world operations, the CAS platform will be competing for system resources just like any other application. As a result, there’s likely to be greater pressure on DRAM usage for the CAS software, so a more reasonable test would be to create larger volumes than the available cache (which is what we do).
Testing Volume Performance
In a recent series of performance tests, we looked at a range of container-attached storage solutions. Our testing script follows the dbench model but with some changes:
- Ramp Time – we increased this value from 2 to 10 seconds to ensure that any file system pre-seeding had completed during testing.
- Run time – this was increased to 30 seconds to ensure that the underlying storage devices weren’t caching I/O in DRAM or benefiting from on-device caching
- Large volumes – tests were run with a typical volume size of 250GB, much larger than the available system DRAM.
- Multiple Tests – each test was run multiple times to validate the results were consistent and ensure that SSDs had been conditioned and were not writing I/O into previously unused parts of the SSD.
Resiliency
As we mentioned earlier, CAS solutions are more like systems than individual devices, so we need to test scenarios that match typical use cases. Container-based solutions initially used local devices (local physical volumes) with no resiliency. The application was expected to manage recovery if a container, pod or server crashed or was lost. In CAS solutions, resiliency is built into the platform. The CAS layer will replicate data between pods across multiple nodes to protect against data loss and failure. We therefore need to test these scenarios to see how well the CAS solution implements resilient data protection and replication across the network.
Our test uses four scenarios:
- Local Volume (no replica) – testing a single mirror provisioned to the same node on which the fio test pod is running. This demonstrates local device performance without any network effects.
- Local Volume (with replica) – a volume on a local host to the fio script, with a LUN replica on another host. This tests the impacts of networking and providing a resilient mirror.
- Remote Volume (no replica) – this test runs fio on a different host to where the test volume is provisioned, measuring the network effect without a second mirror.
- Remote Volume (with replica) – this final test uses a remote volume with a replica provisioned against a third node.
These four tests provide insight into how well each platform manages to implement data resiliency by creating multiple mirrors and to what extent this affects I/O performance to the application.
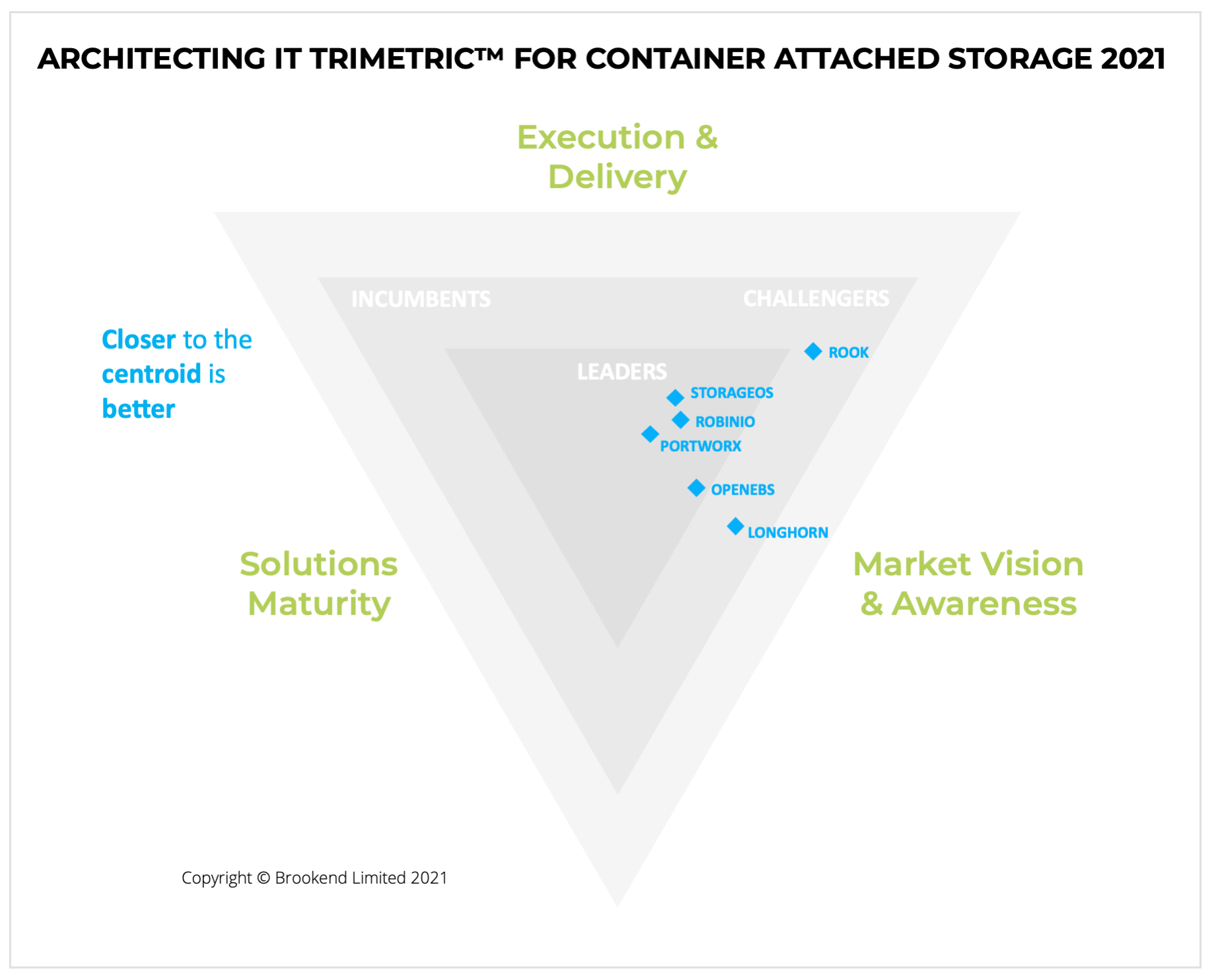
The results of the testing are available here, sponsored with StorageOS, where we look at StorageOS, OpenEBS, Longhorn and Rook/Ceph. (registration required).
Perfection
Is this testing environment perfect? The answer is clearly no because the process doesn’t reflect a real-world scenario. I’ve performed benchmark testing, for example, on enterprise hardware (HDD-based) where single LUN I/O throughput was disappointing, however with hundreds of connected hosts and thousands of LUNs provisioned, the performance remained the same. This system was designed for parallel I/O, so testing one LUN wasn’t indicative of the system’s capability.
- Performance Benchmarks: Reading Between the Lines
- Why Deterministic Storage Performance is Important
- Performance Analysis of SAS/SATA and NVMe SSDs
- Storage Performance: Why I/O Profiling Matters
So far, we haven’t included any CAS testing that measures the impact of data services such as snapshots, thin provisioning, compression or encryption. All of these features will have an impact on I/O performance and could be relevant in future comparisons. Of course, these features are not supported universally in all products, so this level of testing will need to wait a little longer.
The Architect’s View
Raw volume performance represents the simplest of testing regimes but is a starting point for developing more complex test scenarios. The creation of a testing methodology is an iterative process, and with solutions as new as container storage, will change quickly over time. We will be developing our testing process over the coming months and look forward to publishing more information on application-based testing scenarios.
Copyright (c) 2007-2021 – Post #A05B – Brookend Ltd, first published on https://www.architecting.it/blog, do not reproduce without permission.