
Clumio has announced data protection for S3 buckets as an extension to the existing Clumio Protect platform. Do we need to back up S3, and if so, what problem is this new solution offering solving?
Background
It may seem counter-intuitive to put backup in place for large volumes of unstructured data. Historically, S3 and other object stores were a target for largely inactive data that was seen as a toxic waste dump where data goes to die – rather than a treasure trove of future opportunity.
Of course, this view couldn’t be further from the truth. Businesses are deliberately creating new sources of data that can be analysed to develop long-term business value. Many applications now use active S3 buckets as a repository for unstructured content that doesn’t need to reside in a hierarchical file system.
Justification
So, one way or another, protecting S3 data is a logical step to take. There are also some other considerations.
- S3 is not infallible. Anyone who’s worked with S3 for any length of time will know that the underlying S3 architecture consists of a catalogue and objects on disk. It’s possible for the catalogue to get out of sync, losing data in the process. While the likelihood of this is rare, it’s not zero risk.
- S3 doesn’t do data optimisation. The platform may implement deduplication and compression behind the scenes, but these benefits are not passed onto the customer. Multiple instances of the same document (for example, with versioning) will all attract full price.
- Versioning isn’t efficient. With versioning enabled on an active S3 archive, the costs can increase significantly, as each partially changed object is treated as an entirely new copy of data.
- Buckets can be compromised. Data loss can occur due to ineffective security controls implemented in the first instance or from the results of a ransomware attack.
- Compliance. Regulated industries will need to protect and manage unstructured data, especially if it contains PII (personally identifiable information).
As unstructured data becomes more integrated into core business processes, then the need for backup copies becomes ever more prevalent.
Clumio Protect for S3
Clumio has evolved to a purely cloud-based protection model and currently offers coverage for AWS EBS volumes, EC2 instances, RDS databases and VMware Cloud on AWS. The S3 protection feature extends these capabilities by introducing backup for one or more S3 buckets into Clumio SecureVault. The credentials for SecureVault are separate from those of the customer, providing an air-gap to protect against ransomware attacks. See figure 1 for more details. As this diagram shows, although SecureVault buckets are also on AWS, the relationship between source and target buckets doesn’t have to be one-to-one.
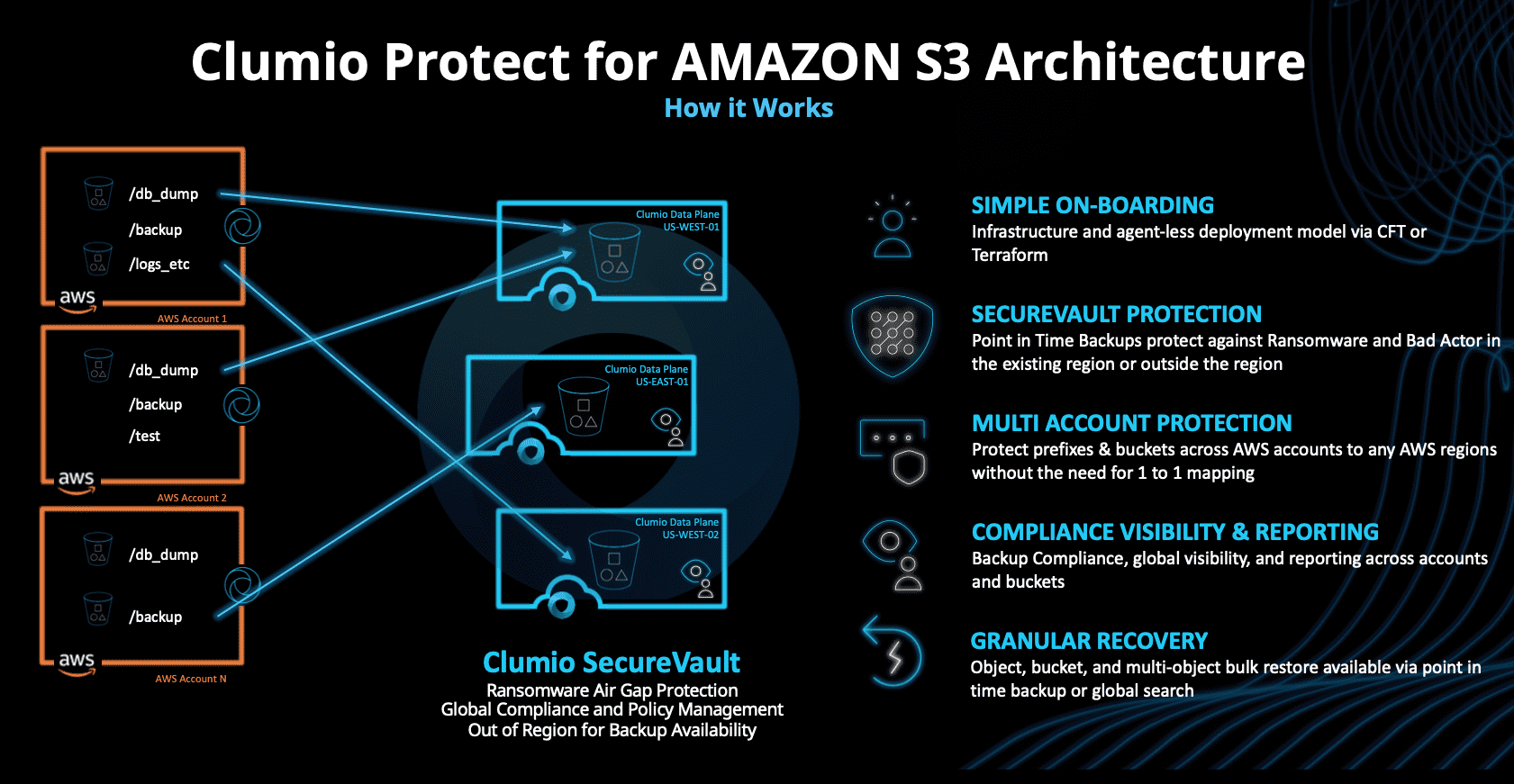
In our briefing with Chadd Kenney (VP and Chief Technologist with Clumio), we asked the most obvious data protection question – what is the data mover? In the Clumio architecture, data movement is managed directly by S3 through standard API calls (once the customer has permitted access). As new data hits the SecureVault buckets, Lamdba calls are used to process and index the content. The most obvious benefit of this design is that it scales automatically. Clumio relies on the underlying features of S3 rather than needing to spin up many virtual machine instances.
Classification
Versioning within S3 is an all-or-nothing approach. However, backed-up and archived objects don’t all need the same level of retention. Data classification is a process of determining the lifecycle of data (including retained copies) from creation to deletion. The process has been in place for decades, with varying levels of success. Clumio Protect for S3 gives the capability to selectively filter objects and apply classification rules to them. In this way, a single bucket can hold multiple data types with a range of retention requirements.
The Architect’s View™
In common with many IT solutions and services, S3 features don’t have the level of granularity required by advanced users. This post is a quick review of the capabilities in Clumio Protect for S3 that highlights why additional levels of protection are needed, both from a security and efficiency perspective. Although the Clumio platform is aimed at data protection, the solution also provides a form of data archiving and management. This makes me wonder whether the Clumio solution could be extended to offer complete data management capabilities.
This idea is not without precedent. Scality introduced Zenko to provide multi-cloud data management. StorReduce (acquired by Pure Storage) was a solution to de-duplicate data and optimise costs for data within S3 buckets. We recently recorded a podcast discussing storage SANs in the cloud, where distributed storage already exists. It’s also worth bearing in mind that native archive and versioning will lock users into the S3 platform. This might be perfectly acceptable, however over time (and assuming Clumio support was there), the ability to move data between providers may be a future requirement. Abstracting from the platform would make this process easier – although the dependency would then be on Clumio, not AWS.
Whether Clumio moves to total data management or not, protecting S3 is still a requirement for today and one that all businesses should be evaluating.
Related Posts
- AWS Introduces Cheaper, Less Reliable S3 Option
- Object Storage: Validating S3 Compatibility
- Object Storage: S3 API Advanced Features
- Object Storage: S3 API and Security
- Object Storage: Standardising on the S3 API
- Has S3 Become the De-Factor API Standard?
- #155 – Introduction to Clumio with Chadd Kenney
Copyright (c) 2007-2021 – Post #f91e – Brookend Ltd, first published on https://www.architecting.it/blog, do not reproduce without permission.